Posts for Tag: visualization
Tioga Pass (Yosemite) Opening Dates
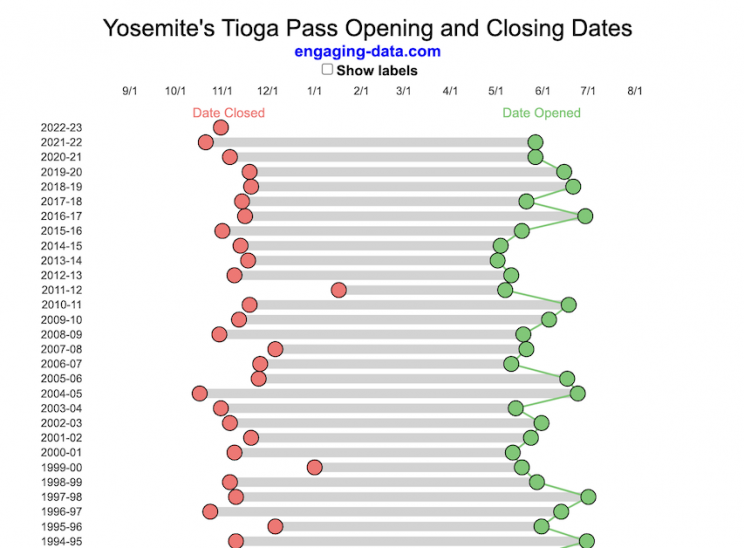
When does Tioga Pass in Yosemite typically open?
The graph shows the closing and opening dates of Tioga pass in Yosemite National Park for each winter season from 1933 to the present. Tioga pass is a mountain pass on State Highway 120 in California’s Sierra Nevada mountain range and one of the entrances to Yosemite NP. The pass itself peaks at 9945 ft above sea level. Each winter it gets a ton of snow, but also with a great deal of variability, which really affects when it can be plowed and the road reopened.
Our family likes to go to Yosemite in June after the kids school lets out and sometimes Hwy 120 and Tioga Pass can often be closed at this time, which limits which areas of the park you can visit. So I often look at data on when the road has opened before and thought it would be a good thing to visualize.
You can toggle the labels on the graph that show the dates of opening and closing as well as the number of days that the pass was closed each winter. Hovering (or clicking) on the circles on the graph will give you a pop up which gives you the exact date.
Data and Tools
The data comes from the US National Park Service for most recent data as well as Mono Basin Clearinghouse for earlier data going back to 1933. Data was organized and compiled in MS Excel. Visualization was done in javascript and specifically the plotly visualization library.
Wordle Stats – How Hard is Today’s Wordle?
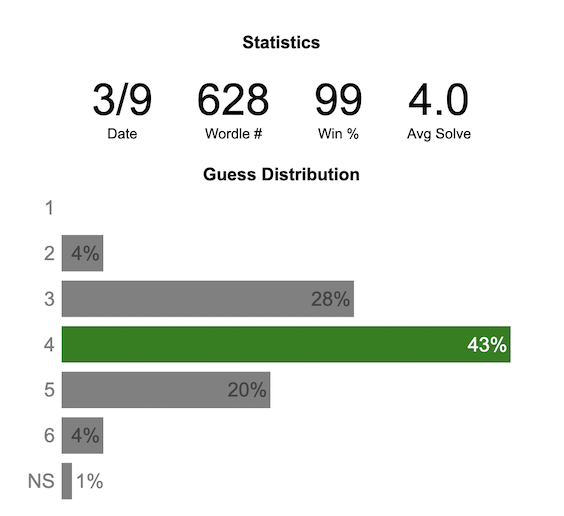
Update: Added a histogram below main graph to view the difficulty of today’s puzzle in context of historical data (compared to a number of previous puzzles)
What is today’s Wordle difficulty?
NY Times’ Wordle is a game of highs and lows. Sometimes your guesses are lucky (I mean, highly skilled) and you can solve the puzzle easily and sometimes you barely get it in 6 guesses. When the latter happens, sometimes you want validation that that day’s puzzle was hard. This dataviz lets you see how difficult today’s wordle puzzle was for other NY Times Wordle players did.
The graph shows the distribution of guesses needed to solve today’s Wordle puzzle, rounded to the nearest whole percent. It also colors the most common number of guesses to solve the puzzle in green and calculates the average number of guesses. “NS” stands for Not Solved. The lower histogram provides some context for how difficult the day’s puzzle is compared to many other puzzles in the past based on average number of guesses needed to solve the puzzle. It doesn’t include the entire history of wordle, but a subset of days that I was able to gather data on.
Even over 1 year later, I still enjoy playing Wordle. I even made a few Wordle games myself – Wordguessr – Tridle – Scrabwordle. I’ve been enjoying the Wordlebot which does a daily analysis of your game. I especially enjoy how it indicates how “lucky” your guesses were and how they eliminated possible answers until you arrive at the puzzle solution. One thing it also provides is data on the frequency of guesses that are made which provides information on the number of guesses it took to solve each puzzle.
Instructions
Click on the eye to get the answer to the day’s puzzle.
Select “Hard Mode” from the dropdown menu in order to see the statistics for hard mode
Data and Tools
The data comes from playing NY Times Wordle game and using their Wordlebot. Python is used to extract the data and wrangle the data into a clean format. Visualization was done in javascript and specifically the plotly visualization library.
Colorado River Reservoir Levels
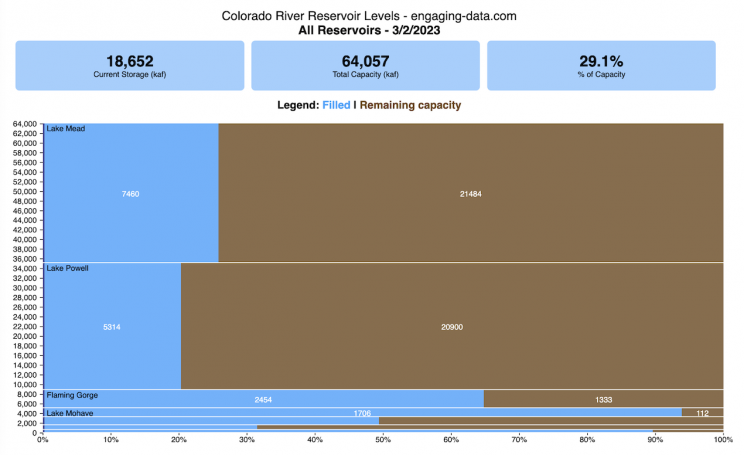
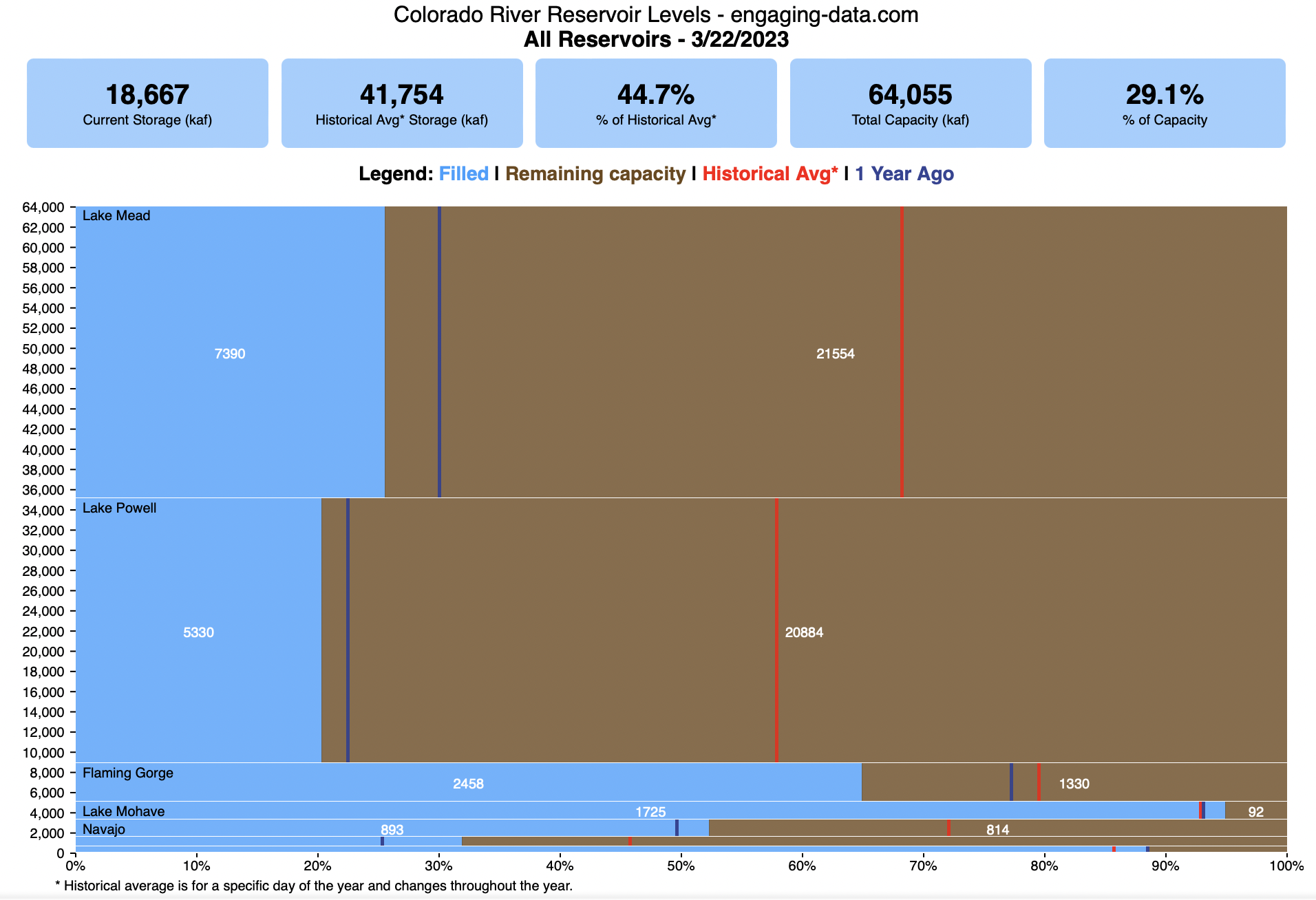
How much water is in the main Colorado River reservoirs?
Check out my California Reservoir Levels Dashboard
I based this graph off of my California Reservoir marimekko graph, because many folks were interested in seeing a similar figure for the Colorado river reservoirs.
This is a marimekko (or mekko) graph which may take some time to understand if you aren’t used to seeing them. Each “row” represents one reservoir, with bars showing how much of the reservoir is filled (blue) and unfilled (brown). The height of the “row” indicates how much water the reservoir could hold. Lake Mead is the reservoir with the largest capacity (at almost 29,000 kaf) and so it is the tallest row. The proportion of blue to brown will show how full it is. As with the California version of this graph, there are also lines that represent historical levels, including historical median level for the day of the year (in red) and the 1 year ago level, which is shown as a dark blue line. I also added the “Deadpool” level for the two largest reservoirs. This is the level at which water cannot flow past the dam and is stuck in the reservoir.
Lake Mead and Lake Powell are by far the largest of these reservoirs and also included are several smaller reservoirs (relative to these two) so the bars will be very thin to the point where they are barely a sliver or may not even show up.
Historical Data
Historical data comes from https://www.water-data.com/ and differs for each reservoir.
- Lake Mead – 1941 to 2015
- Lake Powell – 1964 to 2015
- Flaming Gorge – 1972 to 2015
- Lake Mohave – 1952 to 2015
- Lake Navajo – 1969 to 2015
- Blue Mesa – 1969 to 2015
- Lake Havasu – 1939 to 2015
The daily data for each reservoir was captured in this time period and median value for each day of the calendar year was calculated and this is shown as the red line on the graph.
Instructions:
If you are on a computer, you can hover your cursor over a reservoir and the dashboard at the top will provide information about that individual reservoir. If you are on a mobile device you can tap the reservoir to get that same info. It’s not possible to see or really interact with the tiniest slivers. The main goal of this visualization is to provide a quick overview of the status of the main reservoirs along the Colorado River (or that provide water to the Colorado).
Units are in kaf, thousands of acre feet. 1 kaf is the amount of water that would cover 1 acre in one thousand feet of water (or 1000 acres in water in 1 foot of water). It is also the amount of water in a cube that is 352 feet per side (about the length of a football field). Lake Mead is very large and could hold about 35 cubic kilometers of water at full (but not flood) capacity.
Data and Tools
The data on water storage comes from the US Bureau of Reclamation’s Lower Colorado River Water Operations website. Historical reservoir levels comes from the water-data.com website. Python is used to extract the data and wrangle the data in to a clean format, using the Pandas data analysis library. Visualization was done in javascript and specifically the D3.js visualization library.
California Snowpack Levels Visualization
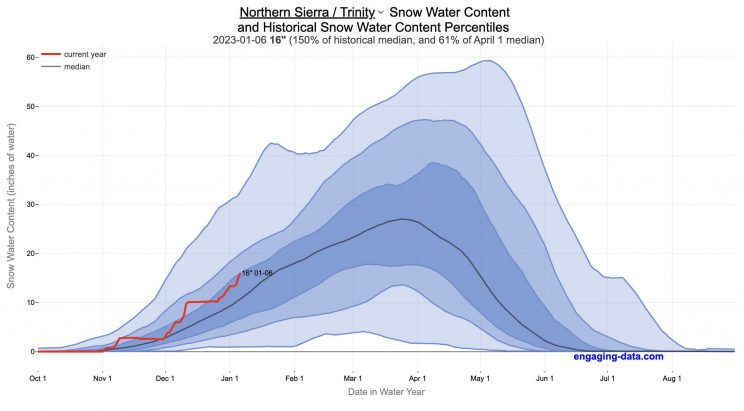
How does the current California snowpack compare with Historical Averages?
If you are looking at this it’s probably winter in California and hopefully snowy in the mountains. In the winter, snow is one of the primary ways that water is stored in California and is on the same order of magnitude as the amount of water in reservoirs.
When I made this graph of California snowpack levels (Jan 2023) we’ve had quite a bit of rain and snow so far and so I wanted to visualize how this year compares with historical levels for this time of year. This graph will provide a constantly updated way to keep tabs on the water content in the Sierra snowpack.
Snow water content is just what it sounds like. It is an estimate of the water content of the snow. Since snow can have be relatively dry or moist, and can be fluffy or compacted, measuring snow depth is not as accurate as measuring the amount of water in the snow. There are multiple ways of measuring the water content of snow, including pads under the snow that measure the weight of the overlying snow, sensors that use sound waves and weighing snow cores.
I used data for California snow water content totals from the California Department of Water Resources. Other California water-related visualizations include reservoir levels in the state as well.
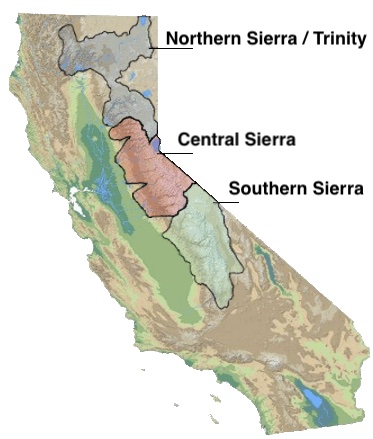
There are three sets of stations (and a state average) that are tracked in the data and these plots:
- Northern Sierra/Trinity – (32 snow sensors)
- Central Sierra – (57 snow sensors)
- Southern Sierra – (36 snow sensors)
- State-wide average – (125 snow sensors)
Here is a map showing these three regions.
These stations are tracked because they provide important information about the state’s water supply (most of which originates from the Sierra Nevada Mountains). Winter and spring snowpack forms an important reservoir of water storage for the state as this melting snow will eventually flow into the state’s rivers and reservoirs to serve domestic and agricultural water needs.
The visualization consists of a graph that shows the range of historical values for snow water content as a function of the day of the year. This range is split into percentiles of snow, spreading out like a cone from the start of the water year (October 1) ramping up to the peak in April and then converging back to zero in summertime. You can see the current water year plotted on this in red to show how it compares to historical values.
My numbers may differ slightly from the numbers reported on the state’s website. The historical percentiles that I calculated are from 1970 until 2022 while I notice the state’s average is between 1990 and 2020.
You can hover (or click) on the graph to audit the data a little more clearly.
Sources and Tools
Data is downloaded from the California Data Exchange Center website of the California Department of Water Resources using a python script. The data is processed in javascript and visualized here using HTML, CSS and javascript and the open source Plotly javascript graphing library.
Splitting the US by Population
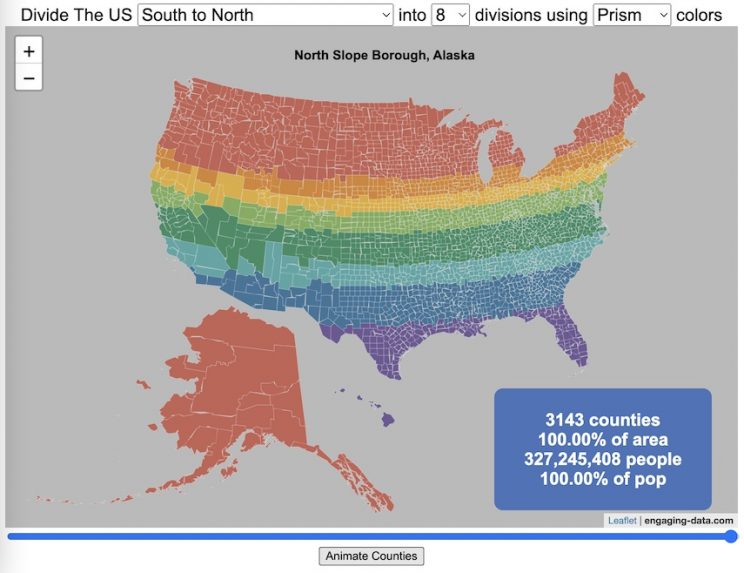
This visualization lets you divide the US into 1,2,3,4,5,8 and 10 different segments with equal population and across different dimensions. The divisions are made using counties as the building blocks (of which there are 3143 in the US). There are numerous different ways to make the divisions. This lets you make the divisions by different types of geographic directions and divisions by population density.
Instructions
- Select a dimension on which to divide up the country – there are geographic dimensions, like north to south or east to west, or by population density
- For some geographic divisions (concentric rings or pie slices), you can choose the geographic center of the divisions
- You can also choose the number and color scheme of the divisions
- To show the divisions, either click the Animate Counties button or use the slider to add counties
If you can think of other interesting ways to divide up the US, please let me know and I can try to add them to this visualization.
Sources and Tools:
2018 county population data is from US Census Bureau. The map visualization is created using the Leaflet javascript mapping library and the data wrangling and user interface and interactivity are created using HTML, CSS and Javascript code.
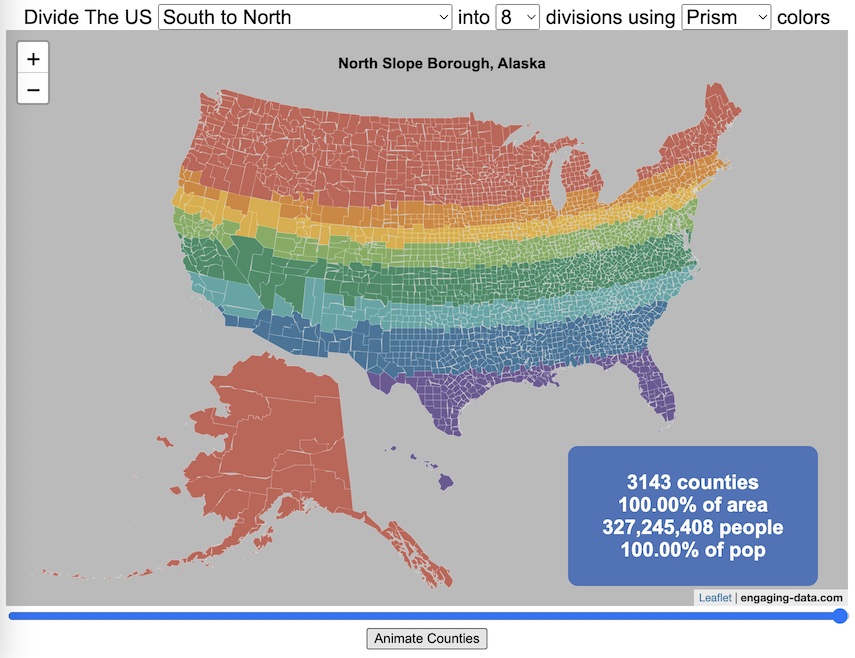
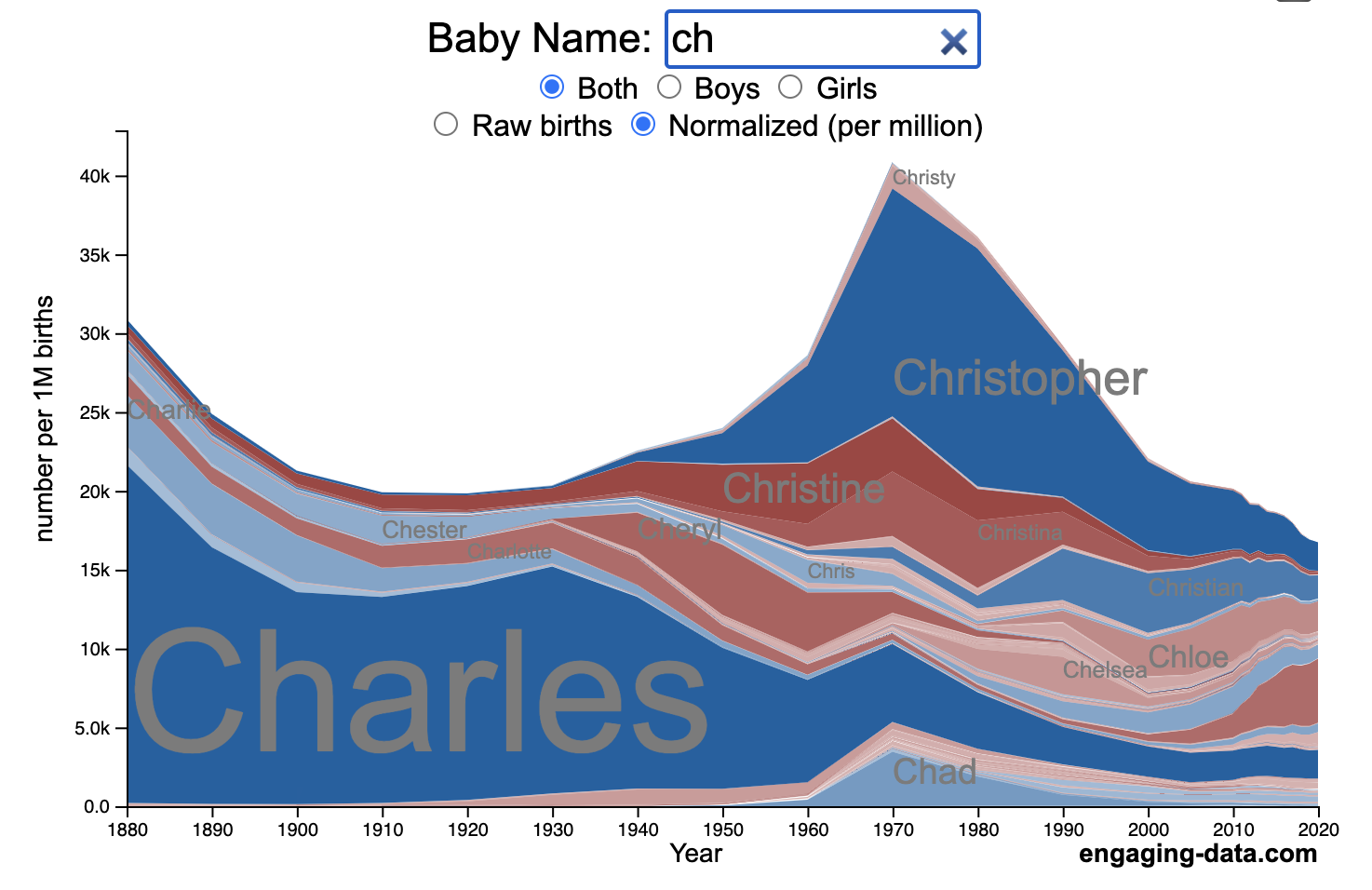
US Baby Name Popularity Visualizer
I added a share button (arrow button) that lets you send a graph with specific name. It copies a custom URL to your clipboard which you can paste into a message/tweet/email.
How popular is your name in US history?
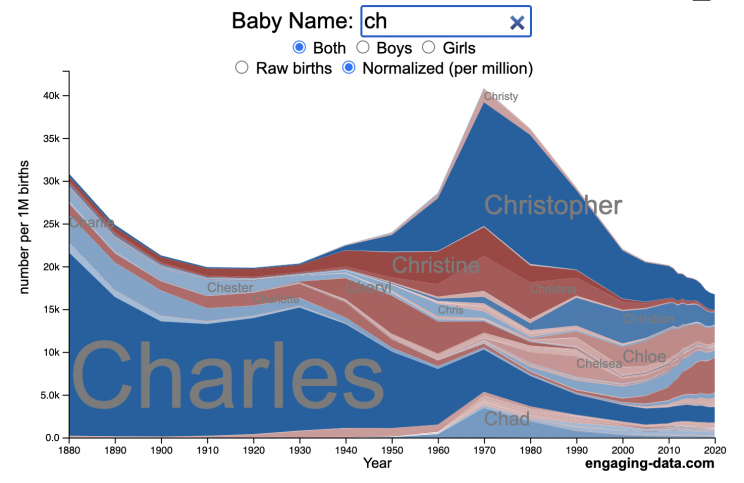
Use this visualization to explore statistics about names, specifically the popularity of different names throughout US history (1880 until 2020). This is a useful tool for seeing the rise (and fall) of popularity of names. Look at names that we think of as old-fashioned, and names that are more modern.
Instructions
- Start typing a name into the input box above and the visualization will show all the names that begin with those letters. The graph will show the historical popularity of all these names as an area graph.
- You can hover (or click on mobile) to bring up a tooltip (popup) that shows you the exact number of births with that name for different years (or decades) and the names rank in that time period.
- It’s best used on computer (rather than a mobile or tablet device) so you can see the graph more clearly and also, if you click on a name wedge, it will zoom into names that begin with those letters.
- You can select different views, Boy names, Girl names or both, as well as looking at the raw number of births or a normalized popularity that accounts for the differential number of births throughout the period between 1880 and 2020.
- If you click the share (arrow) button, it will copy the parameters of the current graph you are looking at and create a custom URL to share with others. It copes the link into your clipboard and your browser’s address (URL) bar.
Isn’t there something out there like this already? Baby Name Wizard and Baby Name Voyager
This visualization is not my original idea, but rather a re-creation of the Baby Name Voyager (from the Baby Name Wizard website) created by Laura Wattenberg. The original visualization disappeared (for some unknown reason) from the web, and I thought it was a shame that we should be deprived of such a fun resource.
It started about a week ago, when I saw on twitter that the Baby Name Wizard website was gone. Here’s the blog post from Laura. I hadn’t used it in probably a decade, but it flashed me back to many years ago well before I got into web programming and dataviz and I remember seeing the Baby Name Voyager and thinking how amazing it was that someone could even make such a thing. Everyone I knew played with it quite a bit when it first came out. It got me thinking that it should still be around and that I could probably make it now with my programming skills and how cool that would be.
So I downloaded the frequency data for Baby Names from the US Social Security Administration and set to work trying to create a stacked area graph of baby names vs time. I started with my go to library for fast dataviz (Plotly.js) but eventually ended up creating the visualization in d3.js which is harder for me, but made it very responsive. I’m not an expert in d3, but know enough that using some similar examples and with lots of googling and stack overflow, I could create what I wanted.
I emailed Laura after creating a sample version, just to make sure it was okay to re-create it as a tribute to the Baby Name Wizard / Voyager and got the okay from her.
Where does the data come from?
Some info about Data (from SSA Baby Names Website):
All names are from Social Security card applications for births that occurred in the United States after 1879. Note that many people born before 1937 never applied for a Social Security card, so their names are not included in our data.
Name data are tabulated from the “First Name” field of the Social Security Card Application. Hyphens and spaces are removed, thus Julie-Anne, Julie Anne, and Julieanne will be counted as a single entry.
Name data are not edited. For example, the sex associated with a name may be incorrect.
Different spellings of similar names are not combined. For example, the names Caitlin, Caitlyn, Kaitlin, Kaitlyn, Kaitlynn, Katelyn, and Katelynn are considered separate names and each has its own rank.
All data are from a 100% sample of our records on Social Security card applications as of March 2021.
I did notice that there was a significant under-representation of male names in the early data (before 1910) relative to female names. In the normalized data, I set the data for each sex to 500,000 male and 500,000 female births per million total births, instead of the actual data which shows approximately double the number of female names than male names. Not sure why females would have higher rates of social security applications in the early 20th century. Update: A helpful Redditor pointed me to this blog post which explains some of the wonkiness of the early data. The gist of it is that Social Security cards and numbers weren’t really a thing until 1935. Thus the names of births in 1880 are actually 55 year olds who applied for Social Security numbers and since they weren’t mandatory, they don’t include everyone. My correction basically makes the assumption that this data is actually a survey and we got uneven samples from males and female respondents. It’s not perfect (like the later data) but it’s a decent representation of name distribution.
Sources and Tools:
The biggest source of inspiration was of course, Laura Wattenberg’s original Baby Name Explorer.
I downloaded the baby names from the Social Security website. Thanks to Michael W. Shackleford at the SSA for starting their name data reporting. I used a python script to parse and organize the historical data into the proper format my javascript. The visualization is created using HTML, CSS and Javascript code (and the d3.js visualization library) to create interactivity and UI. Curran Kelleher’s area label d3 javascript library was a huge help for adding the names to the graph.
Tioga Pass (Yosemite) Opening Dates
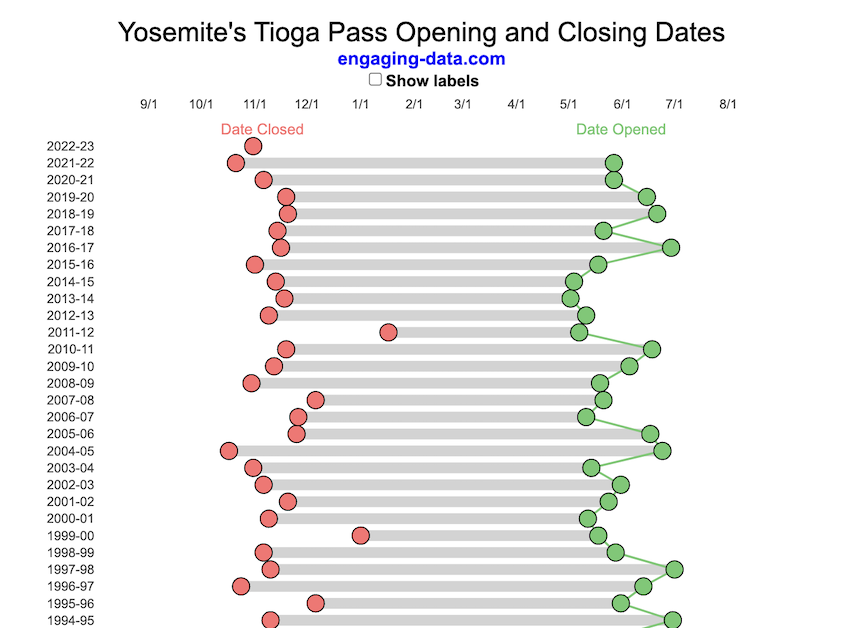
When does Tioga Pass in Yosemite typically open?
The graph shows the closing and opening dates of Tioga pass in Yosemite National Park for each winter season from 1933 to the present. Tioga pass is a mountain pass on State Highway 120 in California’s Sierra Nevada mountain range and one of the entrances to Yosemite NP. The pass itself peaks at 9945 ft above sea level. Each winter it gets a ton of snow, but also with a great deal of variability, which really affects when it can be plowed and the road reopened.
Our family likes to go to Yosemite in June after the kids school lets out and sometimes Hwy 120 and Tioga Pass can often be closed at this time, which limits which areas of the park you can visit. So I often look at data on when the road has opened before and thought it would be a good thing to visualize.
You can toggle the labels on the graph that show the dates of opening and closing as well as the number of days that the pass was closed each winter. Hovering (or clicking) on the circles on the graph will give you a pop up which gives you the exact date.
Data and Tools
The data comes from the US National Park Service for most recent data as well as Mono Basin Clearinghouse for earlier data going back to 1933. Data was organized and compiled in MS Excel. Visualization was done in javascript and specifically the plotly visualization library.
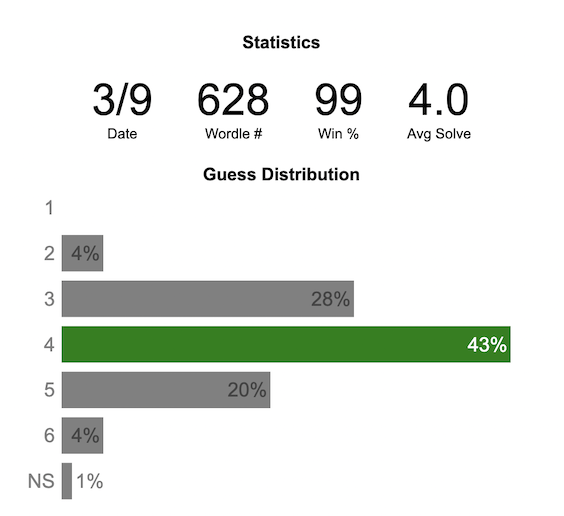
Wordle Stats – How Hard is Today’s Wordle?
Update: Added a histogram below main graph to view the difficulty of today’s puzzle in context of historical data (compared to a number of previous puzzles)
What is today’s Wordle difficulty?
NY Times’ Wordle is a game of highs and lows. Sometimes your guesses are lucky (I mean, highly skilled) and you can solve the puzzle easily and sometimes you barely get it in 6 guesses. When the latter happens, sometimes you want validation that that day’s puzzle was hard. This dataviz lets you see how difficult today’s wordle puzzle was for other NY Times Wordle players did.
The graph shows the distribution of guesses needed to solve today’s Wordle puzzle, rounded to the nearest whole percent. It also colors the most common number of guesses to solve the puzzle in green and calculates the average number of guesses. “NS” stands for Not Solved. The lower histogram provides some context for how difficult the day’s puzzle is compared to many other puzzles in the past based on average number of guesses needed to solve the puzzle. It doesn’t include the entire history of wordle, but a subset of days that I was able to gather data on.
Even over 1 year later, I still enjoy playing Wordle. I even made a few Wordle games myself – Wordguessr – Tridle – Scrabwordle. I’ve been enjoying the Wordlebot which does a daily analysis of your game. I especially enjoy how it indicates how “lucky” your guesses were and how they eliminated possible answers until you arrive at the puzzle solution. One thing it also provides is data on the frequency of guesses that are made which provides information on the number of guesses it took to solve each puzzle.
Instructions
Data and Tools
The data comes from playing NY Times Wordle game and using their Wordlebot. Python is used to extract the data and wrangle the data into a clean format. Visualization was done in javascript and specifically the plotly visualization library.
Colorado River Reservoir Levels
How much water is in the main Colorado River reservoirs?
Check out my California Reservoir Levels Dashboard
I based this graph off of my California Reservoir marimekko graph, because many folks were interested in seeing a similar figure for the Colorado river reservoirs.
This is a marimekko (or mekko) graph which may take some time to understand if you aren’t used to seeing them. Each “row” represents one reservoir, with bars showing how much of the reservoir is filled (blue) and unfilled (brown). The height of the “row” indicates how much water the reservoir could hold. Lake Mead is the reservoir with the largest capacity (at almost 29,000 kaf) and so it is the tallest row. The proportion of blue to brown will show how full it is. As with the California version of this graph, there are also lines that represent historical levels, including historical median level for the day of the year (in red) and the 1 year ago level, which is shown as a dark blue line. I also added the “Deadpool” level for the two largest reservoirs. This is the level at which water cannot flow past the dam and is stuck in the reservoir.
Lake Mead and Lake Powell are by far the largest of these reservoirs and also included are several smaller reservoirs (relative to these two) so the bars will be very thin to the point where they are barely a sliver or may not even show up.
Historical Data
Historical data comes from https://www.water-data.com/ and differs for each reservoir.
- Lake Mead – 1941 to 2015
- Lake Powell – 1964 to 2015
- Flaming Gorge – 1972 to 2015
- Lake Mohave – 1952 to 2015
- Lake Navajo – 1969 to 2015
- Blue Mesa – 1969 to 2015
- Lake Havasu – 1939 to 2015
The daily data for each reservoir was captured in this time period and median value for each day of the calendar year was calculated and this is shown as the red line on the graph.
Instructions:
If you are on a computer, you can hover your cursor over a reservoir and the dashboard at the top will provide information about that individual reservoir. If you are on a mobile device you can tap the reservoir to get that same info. It’s not possible to see or really interact with the tiniest slivers. The main goal of this visualization is to provide a quick overview of the status of the main reservoirs along the Colorado River (or that provide water to the Colorado).
Units are in kaf, thousands of acre feet. 1 kaf is the amount of water that would cover 1 acre in one thousand feet of water (or 1000 acres in water in 1 foot of water). It is also the amount of water in a cube that is 352 feet per side (about the length of a football field). Lake Mead is very large and could hold about 35 cubic kilometers of water at full (but not flood) capacity.
Data and Tools
The data on water storage comes from the US Bureau of Reclamation’s Lower Colorado River Water Operations website. Historical reservoir levels comes from the water-data.com website. Python is used to extract the data and wrangle the data in to a clean format, using the Pandas data analysis library. Visualization was done in javascript and specifically the D3.js visualization library.
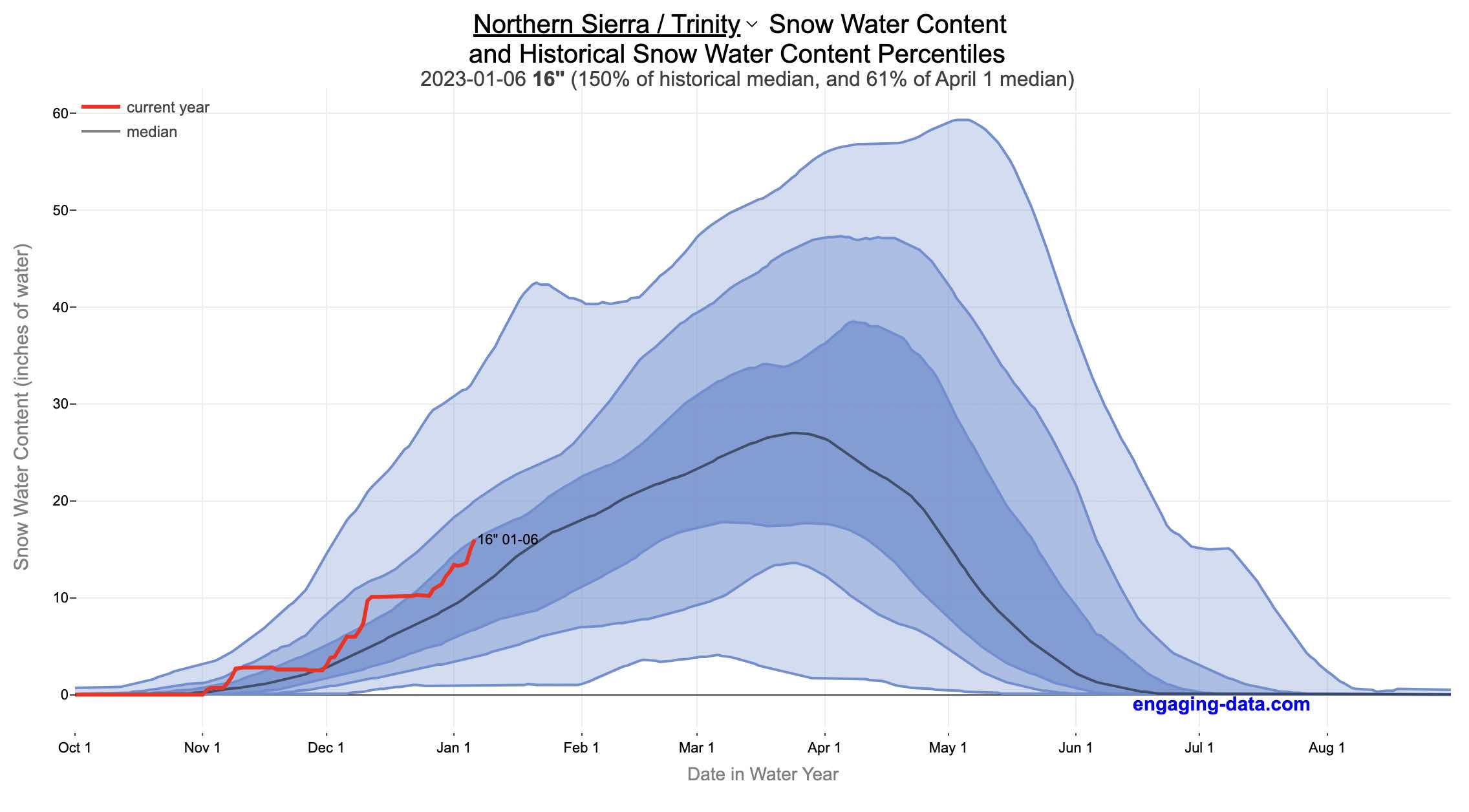
California Snowpack Levels Visualization
How does the current California snowpack compare with Historical Averages?
If you are looking at this it’s probably winter in California and hopefully snowy in the mountains. In the winter, snow is one of the primary ways that water is stored in California and is on the same order of magnitude as the amount of water in reservoirs.
When I made this graph of California snowpack levels (Jan 2023) we’ve had quite a bit of rain and snow so far and so I wanted to visualize how this year compares with historical levels for this time of year. This graph will provide a constantly updated way to keep tabs on the water content in the Sierra snowpack.
Snow water content is just what it sounds like. It is an estimate of the water content of the snow. Since snow can have be relatively dry or moist, and can be fluffy or compacted, measuring snow depth is not as accurate as measuring the amount of water in the snow. There are multiple ways of measuring the water content of snow, including pads under the snow that measure the weight of the overlying snow, sensors that use sound waves and weighing snow cores.
I used data for California snow water content totals from the California Department of Water Resources. Other California water-related visualizations include reservoir levels in the state as well.
There are three sets of stations (and a state average) that are tracked in the data and these plots:
- Northern Sierra/Trinity – (32 snow sensors)
- Central Sierra – (57 snow sensors)
- Southern Sierra – (36 snow sensors)
- State-wide average – (125 snow sensors)
Here is a map showing these three regions.
These stations are tracked because they provide important information about the state’s water supply (most of which originates from the Sierra Nevada Mountains). Winter and spring snowpack forms an important reservoir of water storage for the state as this melting snow will eventually flow into the state’s rivers and reservoirs to serve domestic and agricultural water needs.
The visualization consists of a graph that shows the range of historical values for snow water content as a function of the day of the year. This range is split into percentiles of snow, spreading out like a cone from the start of the water year (October 1) ramping up to the peak in April and then converging back to zero in summertime. You can see the current water year plotted on this in red to show how it compares to historical values.
My numbers may differ slightly from the numbers reported on the state’s website. The historical percentiles that I calculated are from 1970 until 2022 while I notice the state’s average is between 1990 and 2020.
You can hover (or click) on the graph to audit the data a little more clearly.
Sources and Tools
Data is downloaded from the California Data Exchange Center website of the California Department of Water Resources using a python script. The data is processed in javascript and visualized here using HTML, CSS and javascript and the open source Plotly javascript graphing library.
Splitting the US by Population
This visualization lets you divide the US into 1,2,3,4,5,8 and 10 different segments with equal population and across different dimensions. The divisions are made using counties as the building blocks (of which there are 3143 in the US). There are numerous different ways to make the divisions. This lets you make the divisions by different types of geographic directions and divisions by population density.
Instructions
- Select a dimension on which to divide up the country – there are geographic dimensions, like north to south or east to west, or by population density
- For some geographic divisions (concentric rings or pie slices), you can choose the geographic center of the divisions
- You can also choose the number and color scheme of the divisions
- To show the divisions, either click the Animate Counties button or use the slider to add counties
If you can think of other interesting ways to divide up the US, please let me know and I can try to add them to this visualization.
Sources and Tools:
2018 county population data is from US Census Bureau. The map visualization is created using the Leaflet javascript mapping library and the data wrangling and user interface and interactivity are created using HTML, CSS and Javascript code.
US Baby Name Popularity Visualizer
I added a share button (arrow button) that lets you send a graph with specific name. It copies a custom URL to your clipboard which you can paste into a message/tweet/email.
How popular is your name in US history?
Use this visualization to explore statistics about names, specifically the popularity of different names throughout US history (1880 until 2020). This is a useful tool for seeing the rise (and fall) of popularity of names. Look at names that we think of as old-fashioned, and names that are more modern.
Instructions
- Start typing a name into the input box above and the visualization will show all the names that begin with those letters. The graph will show the historical popularity of all these names as an area graph.
- You can hover (or click on mobile) to bring up a tooltip (popup) that shows you the exact number of births with that name for different years (or decades) and the names rank in that time period.
- It’s best used on computer (rather than a mobile or tablet device) so you can see the graph more clearly and also, if you click on a name wedge, it will zoom into names that begin with those letters.
- You can select different views, Boy names, Girl names or both, as well as looking at the raw number of births or a normalized popularity that accounts for the differential number of births throughout the period between 1880 and 2020.
- If you click the share (arrow) button, it will copy the parameters of the current graph you are looking at and create a custom URL to share with others. It copes the link into your clipboard and your browser’s address (URL) bar.
Isn’t there something out there like this already? Baby Name Wizard and Baby Name Voyager
This visualization is not my original idea, but rather a re-creation of the Baby Name Voyager (from the Baby Name Wizard website) created by Laura Wattenberg. The original visualization disappeared (for some unknown reason) from the web, and I thought it was a shame that we should be deprived of such a fun resource.
It started about a week ago, when I saw on twitter that the Baby Name Wizard website was gone. Here’s the blog post from Laura. I hadn’t used it in probably a decade, but it flashed me back to many years ago well before I got into web programming and dataviz and I remember seeing the Baby Name Voyager and thinking how amazing it was that someone could even make such a thing. Everyone I knew played with it quite a bit when it first came out. It got me thinking that it should still be around and that I could probably make it now with my programming skills and how cool that would be.
So I downloaded the frequency data for Baby Names from the US Social Security Administration and set to work trying to create a stacked area graph of baby names vs time. I started with my go to library for fast dataviz (Plotly.js) but eventually ended up creating the visualization in d3.js which is harder for me, but made it very responsive. I’m not an expert in d3, but know enough that using some similar examples and with lots of googling and stack overflow, I could create what I wanted.
I emailed Laura after creating a sample version, just to make sure it was okay to re-create it as a tribute to the Baby Name Wizard / Voyager and got the okay from her.
Where does the data come from?
Some info about Data (from SSA Baby Names Website):
All names are from Social Security card applications for births that occurred in the United States after 1879. Note that many people born before 1937 never applied for a Social Security card, so their names are not included in our data.
Name data are tabulated from the “First Name” field of the Social Security Card Application. Hyphens and spaces are removed, thus Julie-Anne, Julie Anne, and Julieanne will be counted as a single entry.
Name data are not edited. For example, the sex associated with a name may be incorrect.Different spellings of similar names are not combined. For example, the names Caitlin, Caitlyn, Kaitlin, Kaitlyn, Kaitlynn, Katelyn, and Katelynn are considered separate names and each has its own rank.
All data are from a 100% sample of our records on Social Security card applications as of March 2021.
I did notice that there was a significant under-representation of male names in the early data (before 1910) relative to female names. In the normalized data, I set the data for each sex to 500,000 male and 500,000 female births per million total births, instead of the actual data which shows approximately double the number of female names than male names. Not sure why females would have higher rates of social security applications in the early 20th century. Update: A helpful Redditor pointed me to this blog post which explains some of the wonkiness of the early data. The gist of it is that Social Security cards and numbers weren’t really a thing until 1935. Thus the names of births in 1880 are actually 55 year olds who applied for Social Security numbers and since they weren’t mandatory, they don’t include everyone. My correction basically makes the assumption that this data is actually a survey and we got uneven samples from males and female respondents. It’s not perfect (like the later data) but it’s a decent representation of name distribution.
Sources and Tools:
The biggest source of inspiration was of course, Laura Wattenberg’s original Baby Name Explorer.
I downloaded the baby names from the Social Security website. Thanks to Michael W. Shackleford at the SSA for starting their name data reporting. I used a python script to parse and organize the historical data into the proper format my javascript. The visualization is created using HTML, CSS and Javascript code (and the d3.js visualization library) to create interactivity and UI. Curran Kelleher’s area label d3 javascript library was a huge help for adding the names to the graph.
Recent Comments