Posts for Tag: data
Understanding Tax Brackets: Interactive Income Tax Visualization and Calculator
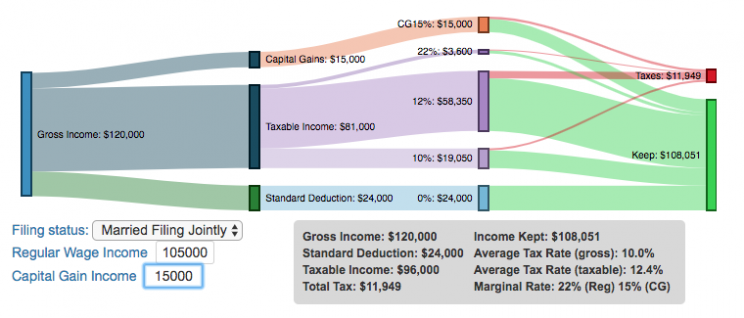
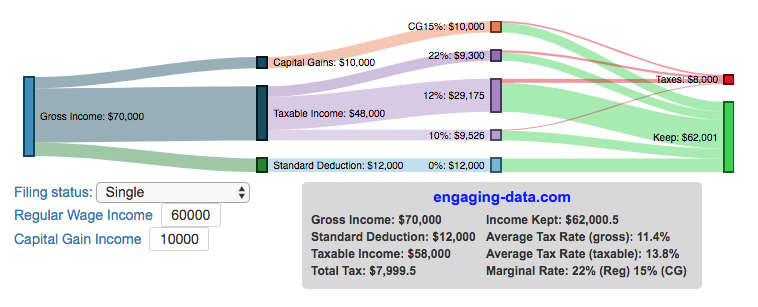
Please check out the newer version of this visualization
How is your income distributed across tax brackets?
I previously made a graphical visualization of income and marginal tax rates to show how tax brackets work. That graph tried to show alot of info on the same graph, i.e. the breakdown of income tax brackets for incomes ranging from $10,000 to $3,000,000. It was nice looking, but I think several people were confused about how to read the graph. This Sankey graph is a more detailed look at the tax breakdown for one specific income. You can enter your (or any other) profile and see how taxes are distributed across the different brackets. It can help (as the other tried) to better understand marginal and average tax rates. This tool only looks at US Federal Income taxes and ignores state, local and Social Security/Medicare taxes.
– Use this button to generate a URL that you can share a specific set of inputs and graphs. Just copy the URL in the address bar at the top of your browser (after pressing the button).
Instructions for using the visual tax calculator:
- Select filing status: Single, Married Filing Jointly or Head of Household. For more info on these filing categories see the IRS website
- Enter your regular income and capital gains income. Regular income is wage or employment income and is taxed at a higher rate than capital gains income. Capital gains income is typically investment income from the sale of stocks or dividends and taxed at a lower rate than regular income.
- Move your cursor or click on the Sankey graph to select a specific link. This will give you more information about how income in a specific tax bracket is being taxed.
**Click Here to view other financial-related tools and data visualizations from engaging-data**
As seen with the marginal rates graph, there is a big difference in how regular income and capital gains are taxed. Capital gains are taxed at a lower rate and generally have larger bracket sizes. Generally, wealthier households earn a greater fraction of their income from capital gains and as a result of the lower tax rates on capital gains, these household pay a lower effective tax rate than those making an order of magnitude less in overall income.
Tax Brackets By Year
This table lets you choose to view the thresholds for each income and capital gains tax bracket for the last few years. You can see that tax rates are much lower for capital gains in the table below than for regular income.
For those not visually inclined, here is a written description of how to apply marginal tax rates. The first thing to note is that the income shown here in the graphs is taxable income, which simply speaking is your gross income with deductions removed. The standard deduction for 2018 range from $12,000 for Single filers to $24,000 for Married filers.
- If you are single, all of your regular taxable income between 0 and $9,525 is taxed at a 10% rate. This means that your all of your gross income below $12,000 is not taxed and your gross income between $12,000 and $21,525 is taxed at 10%.
- If you have more income, you move up a marginal tax bracket. Any taxable income in excess of $9,525 but below $38,700 will be taxed at the 12% rate. It is important to note that not all of your income is taxed at the marginal rate, just the income between these amounts.
- Income between $38,700 and $82,500 is taxed at 24% and so on until you have income over $500,000 and are in the 37% marginal tax rate . . .
- Thus, different parts of your income are taxed at different rates and you can calculate an average or effective rate (which is shown in the summary table).
- Capital gains income complicates things slightly as it is taxed after regular income. Thus any amount of capital gains taxes you make are taxed at a rate that corresponds to starting after you regular income. If you made $100,000 in regular income, and only $100 in capital gains income, that $100 dollars would be taxed at the 15% rate and not at the 0% rate, because the $100,000 in regular income pushes you into the 2nd marginal tax bracket for capital gains (between $38,700 and $426,700).
Data and Tools:
Tax brackets and rates were obtained from the IRS website and calculations were made using javascript and code modified from the Sankeymatic plotting website.
Snake on a Globe

Navigate the globe to the specified cities eating as many apples as you can
I coded a unique twist on the classic snake game, Snake on a Globe, where your mission is to eat as many apples as you can when given their location and find the best ways to navigate the globe.
The game includes the largest cities in the world and tests your geographical knowledge about country and city locations. Your challenge is to move to the next apple and city in the most efficient manner, moving only along lines of longitude or latitude. But remember you are on a sphere so you can move around the globe in any of four directions: over the poles and east and west.
Instructions
Use the arrow keys (or WASD or IJKL) to move up, down, left and right along the lines of longitude and latitude to try to get to the named city.
The score increases for each apple you eat and there are extra bonus points for the largest cities. For each apple you eat, your body gets longer
The game calculates the least number of steps to move between one apple and the next and your score will start to decline once you exceed this number of steps. The game will remind you that your score is going down because it will be shown in red.
The game ends when your score goes to zero (i.e. you took too long to eat an apple) or if you collide with your own body. One caveat is that you can cross over the poles without hitting your own body if you are on a different line of longitude.
See how many apples you can eat and whether you can get a high score.
Sources and Tools:
The list of cities and their population is from Simplemaps. The game is coded with Three Globe and Three.js, 3D javascript libraries in javascript and HTML and CSS.

University of California Admission Rates by Major

Which majors are most competitive across the University of California system?
The University of California consists of nine campuses with undergraduate programs and they are all ranked among the best universities in the US (according to US News). All nine rank within the top 45 public schools including #1 and #2 and top 85 national universities in the US.
This data visualization focuses on the acceptance rates for students based on their indicated preferred majors in their application to the various University of California campuses in the Fall of 2023 admissions cycle. When you apply to a given university campus, you need to specify a major and this choice can affect the student’s chances of getting accepted, especially if the major is very sought after. Subjects like computer science are very popular and as a result, the data shows that most campuses have a lower acceptance rate for computer science as compared to the university as a whole.
Data visualization
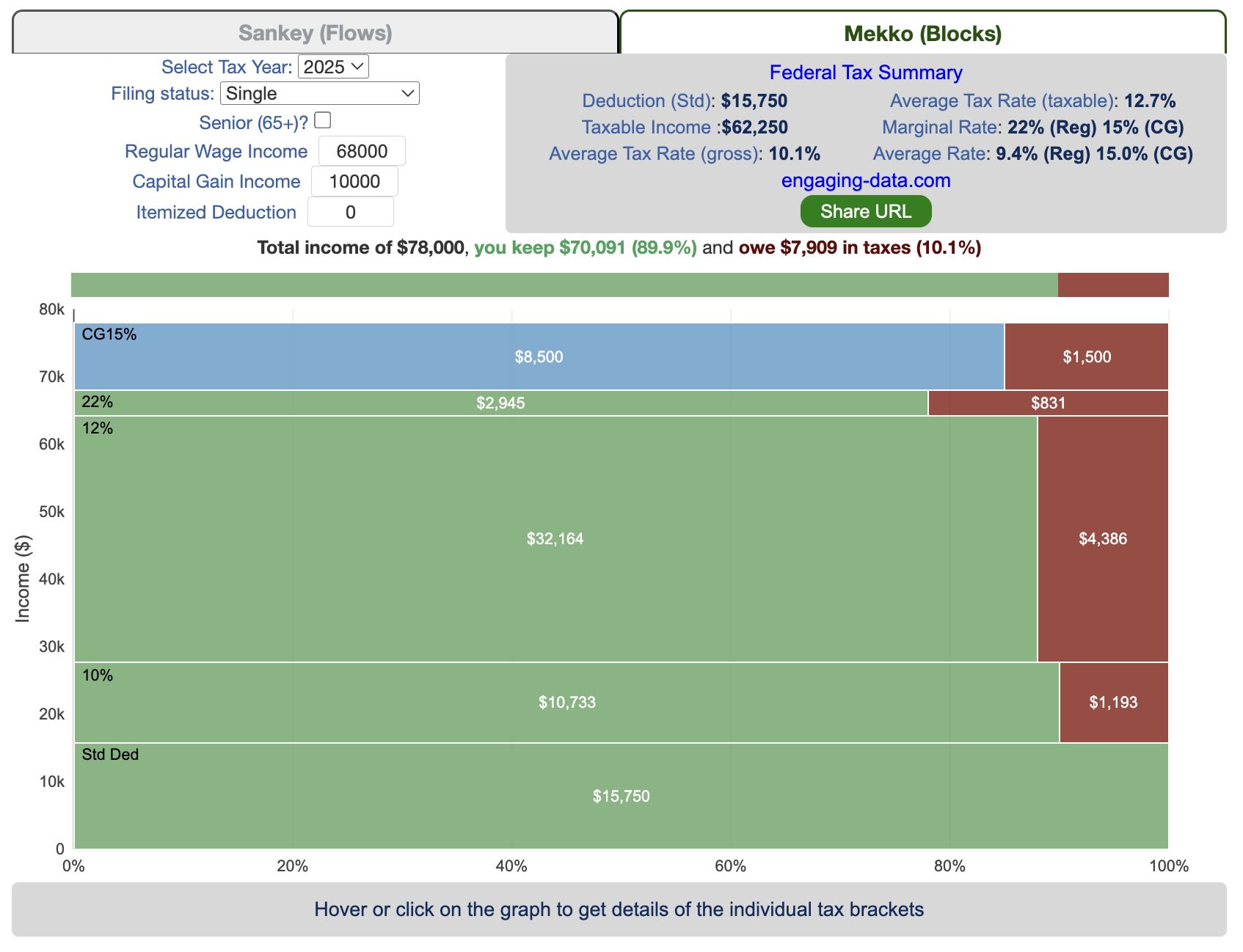
The graph shown in the data visualization is a marimekko graph which shows a percentage based bar graph showing the acceptance rate (in blue) for a given major at a given university. The height of each horizontal bar is proportional to the number of applicants to that major, so taller bars have more applicants vs bars that are shorter. If you hover over (or click on mobile) a bar, it provides more information about the acceptance rate, enrollment rate (i.e. yield rate) and the GPA of accepted students. You can choose to sort the graph by subject name, admit rate or number of applicants.
The data visualization can help you explore different campuses and major categories. If you are viewing “School View“, you can see how the various disciplines compare for a single university at one time. Whereas if you view “Subject View” you can see the comparison of a single discipline across the University campuses that offer those majors.
The University of California has over 240,000 undergraduate students and extends about 140,000 acceptances to fill out 42,000 slots for first year students. There is a significant amount of overlap as most students applying for admission apply to several campuses, and many students get accepted to multiple campuses.
The broad disciplines used in the visualization are composed of a number of individual majors and these are detailed in the table below.
GPA calculation
The University of California only considers grades from 10th grade and 11th grade for admissions decisions, and uses a weighted system where honors and AP classes are given an extra point in GPA calculations above the normal A=4, B=3, C=2, etc. . GPA calculation. So for an honors math class, for example, an A would be worth 5 points.
Sources and Tools:
Data comes directly from the University of California website for the fall of 2023, which has quite a bit of interesting data about students and admissions. I downloaded the data and processed it with python to organize it. The webtool is made using javascript, HTML and CSS and graphed using the open-source plotly graphing library.
Table of Disciplines to majors
This table lists the specific areas and majors that make up the broad disciplines shown in the data visualization.
Broad discipline
CIP Family Title
CIP Subfamily Title
Architecture
ARCHITECTURE AND RELATED SERVICES
Architecture.
Architecture
ARCHITECTURE AND RELATED SERVICES
City/Urban, Community, and Regional Planning.
Architecture
ARCHITECTURE AND RELATED SERVICES
Environmental Design.
Architecture
ARCHITECTURE AND RELATED SERVICES
Landscape Architecture.
Architecture
ARCHITECTURE AND RELATED SERVICES
Real Estate Development.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Linguistic, Comparative, and Related Language Studies and Services.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
African Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
East Asian Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Slavic, Baltic and Albanian Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Germanic Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Romance Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Middle/Near Eastern and Semitic Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Classics and Classical Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Celtic Languages, Literatures, and Linguistics.
Arts & Humanities
FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS
Foreign Languages, Literatures, and Linguistics, Other.
Arts & Humanities
ENGLISH LANGUAGE AND LITERATURE/LETTERS
English Language and Literature, General.
Arts & Humanities
ENGLISH LANGUAGE AND LITERATURE/LETTERS
Rhetoric and Composition/Writing Studies.
Arts & Humanities
ENGLISH LANGUAGE AND LITERATURE/LETTERS
Literature.
Arts & Humanities
ENGLISH LANGUAGE AND LITERATURE/LETTERS
English Language and Literature/Letters, Other.
Arts & Humanities
LIBERAL ARTS AND SCIENCES, GENERAL STUDIES AND HUMANITIES
Liberal Arts and Sciences, General Studies and Humanities.
Arts & Humanities
PHILOSOPHY AND RELIGIOUS STUDIES
Philosophy.
Arts & Humanities
PHILOSOPHY AND RELIGIOUS STUDIES
Religion/Religious Studies.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Visual and Performing Arts, General.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Dance.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Design and Applied Arts.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Drama/Theatre Arts and Stagecraft.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Film/Video and Photographic Arts.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Fine and Studio Arts.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Music.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Arts, Entertainment, and Media Management.
Arts & Humanities
VISUAL AND PERFORMING ARTS
Visual and Performing Arts, Other.
Arts & Humanities
HISTORY
History.
Broad discipline
CIP Family Title
CIP Subfamily Title
Business
BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES
Business Administration, Management and Operations.
Business
BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES
Business/Managerial Economics.
Business
BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES
Human Resources Management and Services.
Business
BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES
Management Information Systems and Services.
Business
BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES
Management Sciences and Quantitative Methods.
Computer Science
COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES
Computer and Information Sciences, General.
Computer Science
COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES
Computer Programming.
Computer Science
COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES
Information Science/Studies.
Computer Science
COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES
Computer Science.
Computer Science
COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES
Computer Software and Media Applications.
Computer Science
COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES
Computer/Information Technology Administration and Management.
Education
EDUCATION
Education, General.
Education
EDUCATION
Social and Philosophical Foundations of Education.
Education
EDUCATION
Special Education and Teaching.
Education
EDUCATION
Teacher Education and Professional Development, Specific Subject Areas.
Engineering
ENGINEERING
Engineering, General.
Engineering
ENGINEERING
Aerospace, Aeronautical, and Astronautical/Space Engineering.
Engineering
ENGINEERING
Agricultural Engineering.
Engineering
ENGINEERING
Biomedical/Medical Engineering.
Engineering
ENGINEERING
Chemical Engineering.
Engineering
ENGINEERING
Civil Engineering.
Engineering
ENGINEERING
Computer Engineering.
Engineering
ENGINEERING
Electrical, Electronics, and Communications Engineering.
Engineering
ENGINEERING
Engineering Physics.
Engineering
ENGINEERING
Engineering Science.
Engineering
ENGINEERING
Environmental/Environmental Health Engineering.
Engineering
ENGINEERING
Materials Engineering.
Engineering
ENGINEERING
Mechanical Engineering.
Engineering
ENGINEERING
Nuclear Engineering.
Engineering
ENGINEERING
Operations Research.
Engineering
ENGINEERING
Geological/Geophysical Engineering.
Engineering
ENGINEERING
Mechatronics, Robotics, and Automation Engineering.
Engineering
ENGINEERING
Biochemical Engineering.
Engineering
ENGINEERING
Biological/Biosystems Engineering.
Engineering
ENGINEERING
Engineering, Other.
Life Sciences
AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS
Animal Sciences.
Life Sciences
AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS
Food Science and Technology.
Life Sciences
AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS
Plant Sciences.
Life Sciences
NATURAL RESOURCES AND CONSERVATION
Natural Resources Conservation and Research.
Life Sciences
NATURAL RESOURCES AND CONSERVATION
Forestry.
Life Sciences
NATURAL RESOURCES AND CONSERVATION
Wildlife and Wildlands Science and Management.
Life Sciences
NATURAL RESOURCES AND CONSERVATION
Natural Resources and Conservation, Other.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Biology, General.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Biochemistry, Biophysics and Molecular Biology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Botany/Plant Biology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Cell/Cellular Biology and Anatomical Sciences.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Microbiological Sciences and Immunology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Zoology/Animal Biology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Genetics.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Physiology, Pathology and Related Sciences.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Pharmacology and Toxicology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Biomathematics, Bioinformatics, and Computational Biology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Biotechnology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Ecology, Evolution, Systematics, and Population Biology.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Neurobiology and Neurosciences.
Life Sciences
BIOLOGICAL AND BIOMEDICAL SCIENCES
Biological and Biomedical Sciences, Other.
Broad discipline
CIP Family Title
CIP Subfamily Title
Nursing
HEALTH PROFESSIONS AND RELATED PROGRAMS
Registered Nursing, Nursing Administration, Nursing Research and Clinical
Other Health Science
HEALTH PROFESSIONS AND RELATED PROGRAMS
Pharmacy, Pharmaceutical Sciences, and Administration.
Other Health Science
HEALTH PROFESSIONS AND RELATED PROGRAMS
Public Health.
Other/ Interdisciplinary
AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS
Agricultural Business and Management.
Other/ Interdisciplinary
AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS
Agricultural Production Operations.
Other/ Interdisciplinary
AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS
International Agriculture.
Other/ Interdisciplinary
COMMUNICATION, JOURNALISM, AND RELATED PROGRAMS
Communication and Media Studies.
Other/ Interdisciplinary
COMMUNICATION, JOURNALISM, AND RELATED PROGRAMS
Journalism.
Other/ Interdisciplinary
LEGAL PROFESSIONS AND STUDIES
Non-Professional Legal Studies.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Peace Studies and Conflict Resolution.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Mathematics and Computer Science.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Medieval and Renaissance Studies.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Science, Technology and Society.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Nutrition Sciences.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
International/Globalization Studies.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Classical and Ancient Studies.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Cognitive Science.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Human Biology.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Marine Sciences.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Sustainability Studies.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Geography and Environmental Studies.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Data Science.
Other/ Interdisciplinary
MULTI/INTERDISCIPLINARY STUDIES
Multi/Interdisciplinary Studies, Other.
Pharmacy
HEALTH PROFESSIONS AND RELATED PROGRAMS
Pharmacy, Pharmaceutical Sciences, and Administration.
Physical Sciences/Math
MATHEMATICS AND STATISTICS
Mathematics.
Physical Sciences/Math
MATHEMATICS AND STATISTICS
Applied Mathematics.
Physical Sciences/Math
MATHEMATICS AND STATISTICS
Statistics.
Physical Sciences/Math
PHYSICAL SCIENCES
Astronomy and Astrophysics.
Physical Sciences/Math
PHYSICAL SCIENCES
Atmospheric Sciences and Meteorology.
Physical Sciences/Math
PHYSICAL SCIENCES
Chemistry.
Physical Sciences/Math
PHYSICAL SCIENCES
Geological and Earth Sciences/Geosciences.
Physical Sciences/Math
PHYSICAL SCIENCES
Physics.
Physical Sciences/Math
PHYSICAL SCIENCES
Materials Sciences.
Physical Sciences/Math
PHYSICAL SCIENCES
Physical Sciences, Other.
Broad discipline
CIP Family Title
CIP Subfamily Title
Public Admin
PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS
Community Organization and Advocacy.
Public Admin
PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS
Public Administration.
Public Admin
PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS
Public Policy Analysis.
Public Admin
PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS
Social Work.
Public Admin
PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS
Public Administration and Social Service Professions, Other.
Public Health
HEALTH PROFESSIONS AND RELATED PROGRAMS
Public Health.
Social Sciences
AGRICULTURAL/ANIMAL/ PLANT/VETERINARY SCIENCE AND RELATED FIELDS
Agricultural Business and Management.
Social Sciences
AREA, ETHNIC, CULTURAL, GENDER, AND GROUP STUDIES
Area Studies.
Social Sciences
AREA, ETHNIC, CULTURAL, GENDER, AND GROUP STUDIES
Ethnic, Cultural Minority, Gender, and Group Studies.
Social Sciences
AREA, ETHNIC, CULTURAL, GENDER, AND GROUP STUDIES
Area, Ethnic, Cultural, Gender, and Group Studies, Other.
Social Sciences
FAMILY AND CONSUMER SCIENCES/HUMAN SCIENCES
Human Development, Family Studies, and Related Services.
Social Sciences
FAMILY AND CONSUMER SCIENCES/HUMAN SCIENCES
Apparel and Textiles.
Social Sciences
PSYCHOLOGY
Psychology, General.
Social Sciences
PSYCHOLOGY
Research and Experimental Psychology.
Social Sciences
PSYCHOLOGY
Clinical, Counseling and Applied Psychology.
Social Sciences
PSYCHOLOGY
Psychology, Other.
Social Sciences
SOCIAL SCIENCES
Social Sciences, General.
Social Sciences
SOCIAL SCIENCES
Anthropology.
Social Sciences
SOCIAL SCIENCES
Archeology.
Social Sciences
SOCIAL SCIENCES
Criminology.
Social Sciences
SOCIAL SCIENCES
Economics.
Social Sciences
SOCIAL SCIENCES
Geography and Cartography.
Social Sciences
SOCIAL SCIENCES
International Relations and National Security Studies.
Social Sciences
SOCIAL SCIENCES
Political Science and Government.
Social Sciences
SOCIAL SCIENCES
Sociology.
Social Sciences
SOCIAL SCIENCES
Urban Studies/Affairs.
Social Sciences
SOCIAL SCIENCES
Social Sciences, Other.

California Electricity Generation
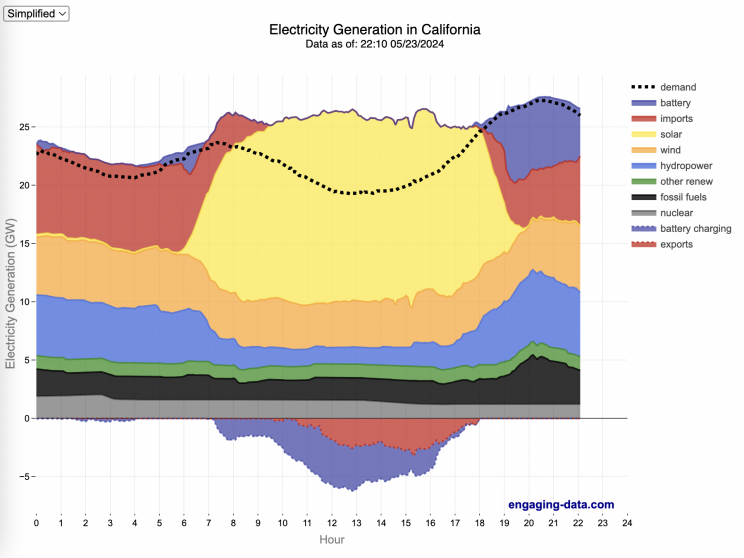
What are the main sources of California’s electricity?
I added the option to view the graph for any day or monthly average from April 2018 to the present using the calendar picker and a daily generation summary
In the United States, electric power plant emissions account for about 25% of greenhouse gas emissions. However, California has been a leader in the transition to clean and renewable energy, driven by ambitious climate policies and a commitment to reducing greenhouse gas emissions. The state has set an electricity target for the state of 60% renewables by 2030 and 100% zero-carbon, clean electricity by 2045. To meet these targets, the state has been investing heavily into solar and wind energy sources. Solar is the largest proportion of California’s electricity grid and California now generates more solar energy than any other state.
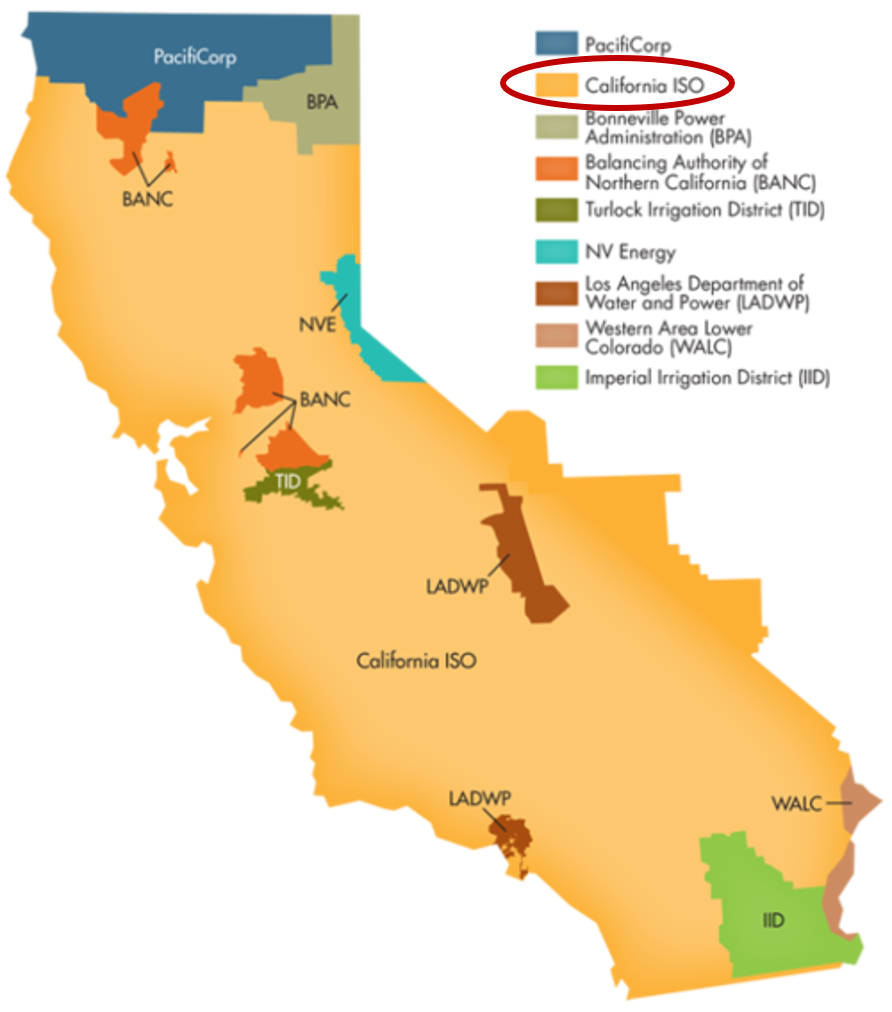
The California Independent System Operator manages the grid for around 32 million Californians or about 80% of the total demand in the state. Here is a map showing the service area and the other electricity districts in the state, the main exceptions include the city of LA and the Sacramento area.
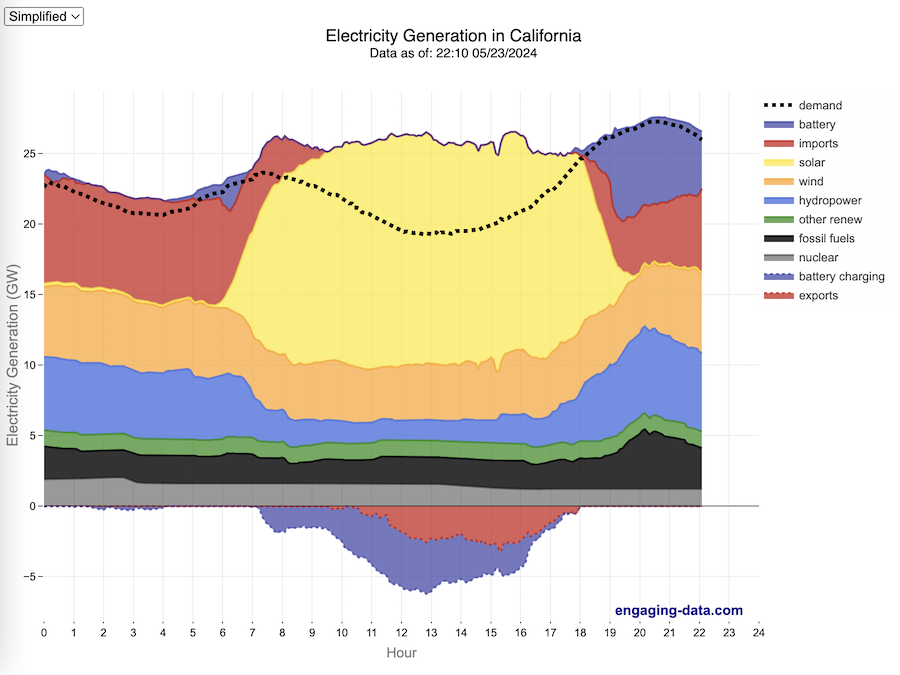
How to read the graph of California’s electricity
The graphs shown here allow us to visualize how electricity generation in the California Independent System Operator (CAISO) region varies over the course of the day. We can see how solar ramps up to be a huge contributor in the middle of the day. And overall, the vast majority of the generation in the state is one form of renewable electricity or another (e.g. solar, wind, hydro, geothermal, biomass and biogas). Add in a small contribution from zero-carbon nuclear energy and we can see that a large majority of power generation comes from zero-carbon sources. It also shows the total electricity demand, which should always be less than the total electricity supply in the state.
Because of the intermittent nature of some renewables, like wind and solar, there are times where the demand for electricity is not able to be met by these sources, and other options are needed to maintain supply demand balance on the state’s grid. To address this issue, the state relies on importing power from outside of the state as well as energy storage (primarily batteries) to meet electricity demand when renewable energy supply is low. If demand is much less than supply, then likely there will be power exported or some charging of batteries. And if demand is less than total generation in the state, power will be imported and/or batteries will be discharged to make up for the power shortfall.
On the graph, positive values from batteries and imports is when those sources are supplying power to the California grid. Negative values for batteries and exports are when there is excess power in the state and batteries are being charged up or power is being exported to neighboring states.
You can view the graph in two forms:
- Detailed – shows all of the power plant fuel types that is provided in the CAISO data: Solar, Wind, Nuclear, Coal, Other, Natural Gas, Large Hydropower, Small Hydropower, Geothermal, Biomass and Biogas. In addition, it shows aggregated net imports into the state from other regions as well as battery discharging or charging.
- Simplified – I aggregated the categories from CAISO into Solar, Wind, Nuclear, Fossil Fuel (including Coal, Other and Natural Gas), Hydro (Large and Small Hydropower), and Other Renewable (Geothermal, Biomass and Biogas). In addition, it shows aggregated net imports into the state from other regions as well as battery discharging or charging.
Also, I added the ability to see yesterday’s data as well. In the future, I will add the ability to see other dates as well.
Data Sources and Tools
Data for electricity sources for California grid comes from the California Independent System Operator (CAISO). This data from this site is downloaded and processed using a python script and updated every 5 minutes. The graph is made using the open source Plotly javascript graphing library.
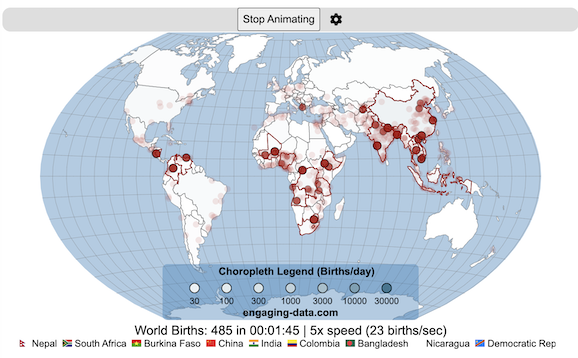
Global Birth Map
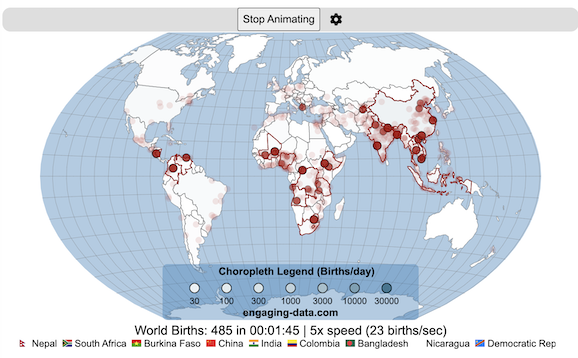
Where in the world are babies being born and how fast?
This interactive, animated map shows the where births are happening across the globe. It doesn’t actually show births in real-time, because data isn’t actually available to do that. However, the map does show the frequency of births that are occurring in different locations across the world. And you can see it in two ways, by country and also geo-referenced to specific locations (along a 1degree grid across the globe). There are many different ways to view this global birth map and these options are laid out in the controls at the top of the map. The scrolling list across the bottom also shows the country of each of the dots on the map.
Instructions
- Speed – change the slider to change the rate at which births show up on the map from real-speed to 25x faster
- Map projection – change the map projection
- Highlight country – an outline around the country when a birth occurs
- Choropleth – Build – as each birth occurs, the background color of the country will slowly change to reflect the number of births in the country
- Choropleth – Show – this option colors all the countries to show the number of births per day that occur in the country
- Dots – Show – this is the main feature that shows where each birth is occurring at the frequency that it does occur.
- Dots – Persist – this feature shows where previous births have occurred and the dots get darker as more births happen in that location.
If you hover (or click on mobile) on a country during the animation, it will display how many births have occurred since the animation stared.
Population distribution data combined with country birthrates
I used data that divided and aggregated the world’s population into 1 degree grid spacing across the globe and I assigned the center of each of these grid locations to a country. Then the country’s annual births (i.e. the country’s population times its birthrate) were distributed across all of the populated locations in each country, weighted by the population distribution (i.e. more populated areas got a greater fraction of the births).
Data Sources and Tools
Population and birthrate data for 2023 was obtained from Wikipedia (Population and birth rates). Population distribution across the globe was obtained from Socioeconomic Data and Applications Center (sedac) at Columbia University.
I used python to process country, population distribution data and parse the data into the probability of a birth at each 1 degree x 1 degree location. Then I used javascript to make random draws and predict the number of births for each map location. D3.js was used to create the map elements and html, css and javascript were used to create the user interface.
Tioga Pass (Yosemite) Opening Dates
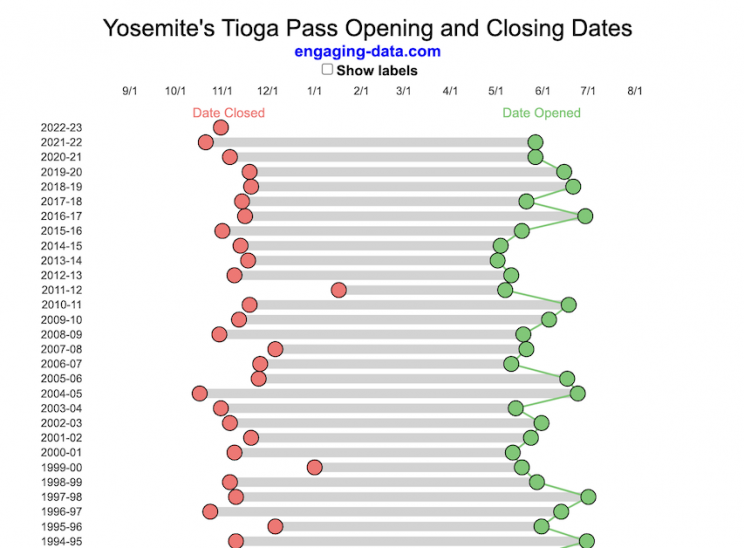
When does Tioga Pass in Yosemite typically open?
The graph shows the closing and opening dates of Tioga pass in Yosemite National Park for each winter season from 1933 to the present. Tioga pass is a mountain pass on State Highway 120 in California’s Sierra Nevada mountain range and one of the entrances to Yosemite NP. The pass itself peaks at 9945 ft above sea level. Each winter it gets a ton of snow, but also with a great deal of variability, which really affects when it can be plowed and the road reopened.
Our family likes to go to Yosemite in June after the kids school lets out and sometimes Hwy 120 and Tioga Pass can often be closed at this time, which limits which areas of the park you can visit. So I often look at data on when the road has opened before and thought it would be a good thing to visualize.
You can toggle the labels on the graph that show the dates of opening and closing as well as the number of days that the pass was closed each winter. Hovering (or clicking) on the circles on the graph will give you a pop up which gives you the exact date.
Data and Tools
The data comes from the US National Park Service for most recent data as well as Mono Basin Clearinghouse for earlier data going back to 1933. Data was organized and compiled in MS Excel. Visualization was done in javascript and specifically the plotly visualization library.
Understanding Tax Brackets: Interactive Income Tax Visualization and Calculator
Please check out the newer version of this visualization
How is your income distributed across tax brackets?
I previously made a graphical visualization of income and marginal tax rates to show how tax brackets work. That graph tried to show alot of info on the same graph, i.e. the breakdown of income tax brackets for incomes ranging from $10,000 to $3,000,000. It was nice looking, but I think several people were confused about how to read the graph. This Sankey graph is a more detailed look at the tax breakdown for one specific income. You can enter your (or any other) profile and see how taxes are distributed across the different brackets. It can help (as the other tried) to better understand marginal and average tax rates. This tool only looks at US Federal Income taxes and ignores state, local and Social Security/Medicare taxes.
– Use this button to generate a URL that you can share a specific set of inputs and graphs. Just copy the URL in the address bar at the top of your browser (after pressing the button).
- Select filing status: Single, Married Filing Jointly or Head of Household. For more info on these filing categories see the IRS website
- Enter your regular income and capital gains income. Regular income is wage or employment income and is taxed at a higher rate than capital gains income. Capital gains income is typically investment income from the sale of stocks or dividends and taxed at a lower rate than regular income.
- Move your cursor or click on the Sankey graph to select a specific link. This will give you more information about how income in a specific tax bracket is being taxed.
**Click Here to view other financial-related tools and data visualizations from engaging-data**
As seen with the marginal rates graph, there is a big difference in how regular income and capital gains are taxed. Capital gains are taxed at a lower rate and generally have larger bracket sizes. Generally, wealthier households earn a greater fraction of their income from capital gains and as a result of the lower tax rates on capital gains, these household pay a lower effective tax rate than those making an order of magnitude less in overall income.
Tax Brackets By Year
This table lets you choose to view the thresholds for each income and capital gains tax bracket for the last few years. You can see that tax rates are much lower for capital gains in the table below than for regular income.
- If you are single, all of your regular taxable income between 0 and $9,525 is taxed at a 10% rate. This means that your all of your gross income below $12,000 is not taxed and your gross income between $12,000 and $21,525 is taxed at 10%.
- If you have more income, you move up a marginal tax bracket. Any taxable income in excess of $9,525 but below $38,700 will be taxed at the 12% rate. It is important to note that not all of your income is taxed at the marginal rate, just the income between these amounts.
- Income between $38,700 and $82,500 is taxed at 24% and so on until you have income over $500,000 and are in the 37% marginal tax rate . . .
- Thus, different parts of your income are taxed at different rates and you can calculate an average or effective rate (which is shown in the summary table).
- Capital gains income complicates things slightly as it is taxed after regular income. Thus any amount of capital gains taxes you make are taxed at a rate that corresponds to starting after you regular income. If you made $100,000 in regular income, and only $100 in capital gains income, that $100 dollars would be taxed at the 15% rate and not at the 0% rate, because the $100,000 in regular income pushes you into the 2nd marginal tax bracket for capital gains (between $38,700 and $426,700).
Data and Tools:
Tax brackets and rates were obtained from the IRS website and calculations were made using javascript and code modified from the Sankeymatic plotting website.
Snake on a Globe
Navigate the globe to the specified cities eating as many apples as you can
I coded a unique twist on the classic snake game, Snake on a Globe, where your mission is to eat as many apples as you can when given their location and find the best ways to navigate the globe.
The game includes the largest cities in the world and tests your geographical knowledge about country and city locations. Your challenge is to move to the next apple and city in the most efficient manner, moving only along lines of longitude or latitude. But remember you are on a sphere so you can move around the globe in any of four directions: over the poles and east and west.
Instructions
Sources and Tools:
The list of cities and their population is from Simplemaps. The game is coded with Three Globe and Three.js, 3D javascript libraries in javascript and HTML and CSS.
University of California Admission Rates by Major
Which majors are most competitive across the University of California system?
The University of California consists of nine campuses with undergraduate programs and they are all ranked among the best universities in the US (according to US News). All nine rank within the top 45 public schools including #1 and #2 and top 85 national universities in the US.
This data visualization focuses on the acceptance rates for students based on their indicated preferred majors in their application to the various University of California campuses in the Fall of 2023 admissions cycle. When you apply to a given university campus, you need to specify a major and this choice can affect the student’s chances of getting accepted, especially if the major is very sought after. Subjects like computer science are very popular and as a result, the data shows that most campuses have a lower acceptance rate for computer science as compared to the university as a whole.
Data visualization
The graph shown in the data visualization is a marimekko graph which shows a percentage based bar graph showing the acceptance rate (in blue) for a given major at a given university. The height of each horizontal bar is proportional to the number of applicants to that major, so taller bars have more applicants vs bars that are shorter. If you hover over (or click on mobile) a bar, it provides more information about the acceptance rate, enrollment rate (i.e. yield rate) and the GPA of accepted students. You can choose to sort the graph by subject name, admit rate or number of applicants.
The data visualization can help you explore different campuses and major categories. If you are viewing “School View“, you can see how the various disciplines compare for a single university at one time. Whereas if you view “Subject View” you can see the comparison of a single discipline across the University campuses that offer those majors.
The University of California has over 240,000 undergraduate students and extends about 140,000 acceptances to fill out 42,000 slots for first year students. There is a significant amount of overlap as most students applying for admission apply to several campuses, and many students get accepted to multiple campuses.
The broad disciplines used in the visualization are composed of a number of individual majors and these are detailed in the table below.
GPA calculation
The University of California only considers grades from 10th grade and 11th grade for admissions decisions, and uses a weighted system where honors and AP classes are given an extra point in GPA calculations above the normal A=4, B=3, C=2, etc. . GPA calculation. So for an honors math class, for example, an A would be worth 5 points.
Sources and Tools:
Data comes directly from the University of California website for the fall of 2023, which has quite a bit of interesting data about students and admissions. I downloaded the data and processed it with python to organize it. The webtool is made using javascript, HTML and CSS and graphed using the open-source plotly graphing library.
Table of Disciplines to majors
This table lists the specific areas and majors that make up the broad disciplines shown in the data visualization.
| Broad discipline | CIP Family Title | CIP Subfamily Title |
|---|---|---|
| Architecture | ARCHITECTURE AND RELATED SERVICES | Architecture. |
| Architecture | ARCHITECTURE AND RELATED SERVICES | City/Urban, Community, and Regional Planning. |
| Architecture | ARCHITECTURE AND RELATED SERVICES | Environmental Design. |
| Architecture | ARCHITECTURE AND RELATED SERVICES | Landscape Architecture. |
| Architecture | ARCHITECTURE AND RELATED SERVICES | Real Estate Development. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Linguistic, Comparative, and Related Language Studies and Services. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | African Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | East Asian Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Slavic, Baltic and Albanian Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Germanic Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Romance Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Middle/Near Eastern and Semitic Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Classics and Classical Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Celtic Languages, Literatures, and Linguistics. |
| Arts & Humanities | FOREIGN LANGUAGES, LITERATURES, AND LINGUISTICS | Foreign Languages, Literatures, and Linguistics, Other. |
| Arts & Humanities | ENGLISH LANGUAGE AND LITERATURE/LETTERS | English Language and Literature, General. |
| Arts & Humanities | ENGLISH LANGUAGE AND LITERATURE/LETTERS | Rhetoric and Composition/Writing Studies. |
| Arts & Humanities | ENGLISH LANGUAGE AND LITERATURE/LETTERS | Literature. |
| Arts & Humanities | ENGLISH LANGUAGE AND LITERATURE/LETTERS | English Language and Literature/Letters, Other. |
| Arts & Humanities | LIBERAL ARTS AND SCIENCES, GENERAL STUDIES AND HUMANITIES | Liberal Arts and Sciences, General Studies and Humanities. |
| Arts & Humanities | PHILOSOPHY AND RELIGIOUS STUDIES | Philosophy. |
| Arts & Humanities | PHILOSOPHY AND RELIGIOUS STUDIES | Religion/Religious Studies. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Visual and Performing Arts, General. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Dance. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Design and Applied Arts. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Drama/Theatre Arts and Stagecraft. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Film/Video and Photographic Arts. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Fine and Studio Arts. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Music. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Arts, Entertainment, and Media Management. |
| Arts & Humanities | VISUAL AND PERFORMING ARTS | Visual and Performing Arts, Other. |
| Arts & Humanities | HISTORY | History. |
| Broad discipline | CIP Family Title | CIP Subfamily Title |
|---|---|---|
| Business | BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES | Business Administration, Management and Operations. |
| Business | BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES | Business/Managerial Economics. |
| Business | BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES | Human Resources Management and Services. |
| Business | BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES | Management Information Systems and Services. |
| Business | BUSINESS, MANAGEMENT, MARKETING, AND RELATED SUPPORT SERVICES | Management Sciences and Quantitative Methods. |
| Computer Science | COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES | Computer and Information Sciences, General. |
| Computer Science | COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES | Computer Programming. |
| Computer Science | COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES | Information Science/Studies. |
| Computer Science | COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES | Computer Science. |
| Computer Science | COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES | Computer Software and Media Applications. |
| Computer Science | COMPUTER AND INFORMATION SCIENCES AND SUPPORT SERVICES | Computer/Information Technology Administration and Management. |
| Education | EDUCATION | Education, General. |
| Education | EDUCATION | Social and Philosophical Foundations of Education. |
| Education | EDUCATION | Special Education and Teaching. |
| Education | EDUCATION | Teacher Education and Professional Development, Specific Subject Areas. |
| Engineering | ENGINEERING | Engineering, General. |
| Engineering | ENGINEERING | Aerospace, Aeronautical, and Astronautical/Space Engineering. |
| Engineering | ENGINEERING | Agricultural Engineering. |
| Engineering | ENGINEERING | Biomedical/Medical Engineering. |
| Engineering | ENGINEERING | Chemical Engineering. |
| Engineering | ENGINEERING | Civil Engineering. |
| Engineering | ENGINEERING | Computer Engineering. |
| Engineering | ENGINEERING | Electrical, Electronics, and Communications Engineering. |
| Engineering | ENGINEERING | Engineering Physics. |
| Engineering | ENGINEERING | Engineering Science. |
| Engineering | ENGINEERING | Environmental/Environmental Health Engineering. |
| Engineering | ENGINEERING | Materials Engineering. |
| Engineering | ENGINEERING | Mechanical Engineering. |
| Engineering | ENGINEERING | Nuclear Engineering. |
| Engineering | ENGINEERING | Operations Research. |
| Engineering | ENGINEERING | Geological/Geophysical Engineering. |
| Engineering | ENGINEERING | Mechatronics, Robotics, and Automation Engineering. |
| Engineering | ENGINEERING | Biochemical Engineering. |
| Engineering | ENGINEERING | Biological/Biosystems Engineering. |
| Engineering | ENGINEERING | Engineering, Other. |
| Life Sciences | AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS | Animal Sciences. |
| Life Sciences | AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS | Food Science and Technology. |
| Life Sciences | AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS | Plant Sciences. |
| Life Sciences | NATURAL RESOURCES AND CONSERVATION | Natural Resources Conservation and Research. |
| Life Sciences | NATURAL RESOURCES AND CONSERVATION | Forestry. |
| Life Sciences | NATURAL RESOURCES AND CONSERVATION | Wildlife and Wildlands Science and Management. |
| Life Sciences | NATURAL RESOURCES AND CONSERVATION | Natural Resources and Conservation, Other. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Biology, General. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Biochemistry, Biophysics and Molecular Biology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Botany/Plant Biology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Cell/Cellular Biology and Anatomical Sciences. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Microbiological Sciences and Immunology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Zoology/Animal Biology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Genetics. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Physiology, Pathology and Related Sciences. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Pharmacology and Toxicology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Biomathematics, Bioinformatics, and Computational Biology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Biotechnology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Ecology, Evolution, Systematics, and Population Biology. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Neurobiology and Neurosciences. |
| Life Sciences | BIOLOGICAL AND BIOMEDICAL SCIENCES | Biological and Biomedical Sciences, Other. |
| Broad discipline | CIP Family Title | CIP Subfamily Title |
|---|---|---|
| Nursing | HEALTH PROFESSIONS AND RELATED PROGRAMS | Registered Nursing, Nursing Administration, Nursing Research and Clinical |
| Other Health Science | HEALTH PROFESSIONS AND RELATED PROGRAMS | Pharmacy, Pharmaceutical Sciences, and Administration. |
| Other Health Science | HEALTH PROFESSIONS AND RELATED PROGRAMS | Public Health. |
| Other/ Interdisciplinary | AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS | Agricultural Business and Management. |
| Other/ Interdisciplinary | AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS | Agricultural Production Operations. |
| Other/ Interdisciplinary | AGRICULTURAL/ ANIMAL/ PLANT/ VETERINARY SCIENCE AND RELATED FIELDS | International Agriculture. |
| Other/ Interdisciplinary | COMMUNICATION, JOURNALISM, AND RELATED PROGRAMS | Communication and Media Studies. |
| Other/ Interdisciplinary | COMMUNICATION, JOURNALISM, AND RELATED PROGRAMS | Journalism. |
| Other/ Interdisciplinary | LEGAL PROFESSIONS AND STUDIES | Non-Professional Legal Studies. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Peace Studies and Conflict Resolution. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Mathematics and Computer Science. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Medieval and Renaissance Studies. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Science, Technology and Society. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Nutrition Sciences. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | International/Globalization Studies. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Classical and Ancient Studies. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Cognitive Science. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Human Biology. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Marine Sciences. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Sustainability Studies. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Geography and Environmental Studies. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Data Science. |
| Other/ Interdisciplinary | MULTI/INTERDISCIPLINARY STUDIES | Multi/Interdisciplinary Studies, Other. |
| Pharmacy | HEALTH PROFESSIONS AND RELATED PROGRAMS | Pharmacy, Pharmaceutical Sciences, and Administration. |
| Physical Sciences/Math | MATHEMATICS AND STATISTICS | Mathematics. |
| Physical Sciences/Math | MATHEMATICS AND STATISTICS | Applied Mathematics. |
| Physical Sciences/Math | MATHEMATICS AND STATISTICS | Statistics. |
| Physical Sciences/Math | PHYSICAL SCIENCES | Astronomy and Astrophysics. |
| Physical Sciences/Math | PHYSICAL SCIENCES | Atmospheric Sciences and Meteorology. |
| Physical Sciences/Math | PHYSICAL SCIENCES | Chemistry. |
| Physical Sciences/Math | PHYSICAL SCIENCES | Geological and Earth Sciences/Geosciences. |
| Physical Sciences/Math | PHYSICAL SCIENCES | Physics. |
| Physical Sciences/Math | PHYSICAL SCIENCES | Materials Sciences. |
| Physical Sciences/Math | PHYSICAL SCIENCES | Physical Sciences, Other. |
| Broad discipline | CIP Family Title | CIP Subfamily Title |
|---|---|---|
| Public Admin | PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS | Community Organization and Advocacy. |
| Public Admin | PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS | Public Administration. |
| Public Admin | PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS | Public Policy Analysis. |
| Public Admin | PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS | Social Work. |
| Public Admin | PUBLIC ADMINISTRATION AND SOCIAL SERVICE PROFESSIONS | Public Administration and Social Service Professions, Other. |
| Public Health | HEALTH PROFESSIONS AND RELATED PROGRAMS | Public Health. |
| Social Sciences | AGRICULTURAL/ANIMAL/ PLANT/VETERINARY SCIENCE AND RELATED FIELDS | Agricultural Business and Management. |
| Social Sciences | AREA, ETHNIC, CULTURAL, GENDER, AND GROUP STUDIES | Area Studies. |
| Social Sciences | AREA, ETHNIC, CULTURAL, GENDER, AND GROUP STUDIES | Ethnic, Cultural Minority, Gender, and Group Studies. |
| Social Sciences | AREA, ETHNIC, CULTURAL, GENDER, AND GROUP STUDIES | Area, Ethnic, Cultural, Gender, and Group Studies, Other. |
| Social Sciences | FAMILY AND CONSUMER SCIENCES/HUMAN SCIENCES | Human Development, Family Studies, and Related Services. |
| Social Sciences | FAMILY AND CONSUMER SCIENCES/HUMAN SCIENCES | Apparel and Textiles. |
| Social Sciences | PSYCHOLOGY | Psychology, General. |
| Social Sciences | PSYCHOLOGY | Research and Experimental Psychology. |
| Social Sciences | PSYCHOLOGY | Clinical, Counseling and Applied Psychology. |
| Social Sciences | PSYCHOLOGY | Psychology, Other. |
| Social Sciences | SOCIAL SCIENCES | Social Sciences, General. |
| Social Sciences | SOCIAL SCIENCES | Anthropology. |
| Social Sciences | SOCIAL SCIENCES | Archeology. |
| Social Sciences | SOCIAL SCIENCES | Criminology. |
| Social Sciences | SOCIAL SCIENCES | Economics. |
| Social Sciences | SOCIAL SCIENCES | Geography and Cartography. |
| Social Sciences | SOCIAL SCIENCES | International Relations and National Security Studies. |
| Social Sciences | SOCIAL SCIENCES | Political Science and Government. |
| Social Sciences | SOCIAL SCIENCES | Sociology. |
| Social Sciences | SOCIAL SCIENCES | Urban Studies/Affairs. |
| Social Sciences | SOCIAL SCIENCES | Social Sciences, Other. |
California Electricity Generation
What are the main sources of California’s electricity?
I added the option to view the graph for any day or monthly average from April 2018 to the present using the calendar picker and a daily generation summary
In the United States, electric power plant emissions account for about 25% of greenhouse gas emissions. However, California has been a leader in the transition to clean and renewable energy, driven by ambitious climate policies and a commitment to reducing greenhouse gas emissions. The state has set an electricity target for the state of 60% renewables by 2030 and 100% zero-carbon, clean electricity by 2045. To meet these targets, the state has been investing heavily into solar and wind energy sources. Solar is the largest proportion of California’s electricity grid and California now generates more solar energy than any other state.
The California Independent System Operator manages the grid for around 32 million Californians or about 80% of the total demand in the state. Here is a map showing the service area and the other electricity districts in the state, the main exceptions include the city of LA and the Sacramento area.
How to read the graph of California’s electricity
The graphs shown here allow us to visualize how electricity generation in the California Independent System Operator (CAISO) region varies over the course of the day. We can see how solar ramps up to be a huge contributor in the middle of the day. And overall, the vast majority of the generation in the state is one form of renewable electricity or another (e.g. solar, wind, hydro, geothermal, biomass and biogas). Add in a small contribution from zero-carbon nuclear energy and we can see that a large majority of power generation comes from zero-carbon sources. It also shows the total electricity demand, which should always be less than the total electricity supply in the state.
Because of the intermittent nature of some renewables, like wind and solar, there are times where the demand for electricity is not able to be met by these sources, and other options are needed to maintain supply demand balance on the state’s grid. To address this issue, the state relies on importing power from outside of the state as well as energy storage (primarily batteries) to meet electricity demand when renewable energy supply is low. If demand is much less than supply, then likely there will be power exported or some charging of batteries. And if demand is less than total generation in the state, power will be imported and/or batteries will be discharged to make up for the power shortfall.
On the graph, positive values from batteries and imports is when those sources are supplying power to the California grid. Negative values for batteries and exports are when there is excess power in the state and batteries are being charged up or power is being exported to neighboring states.
You can view the graph in two forms:
- Detailed – shows all of the power plant fuel types that is provided in the CAISO data: Solar, Wind, Nuclear, Coal, Other, Natural Gas, Large Hydropower, Small Hydropower, Geothermal, Biomass and Biogas. In addition, it shows aggregated net imports into the state from other regions as well as battery discharging or charging.
- Simplified – I aggregated the categories from CAISO into Solar, Wind, Nuclear, Fossil Fuel (including Coal, Other and Natural Gas), Hydro (Large and Small Hydropower), and Other Renewable (Geothermal, Biomass and Biogas). In addition, it shows aggregated net imports into the state from other regions as well as battery discharging or charging.
Also, I added the ability to see yesterday’s data as well. In the future, I will add the ability to see other dates as well.
Data Sources and Tools
Data for electricity sources for California grid comes from the California Independent System Operator (CAISO). This data from this site is downloaded and processed using a python script and updated every 5 minutes. The graph is made using the open source Plotly javascript graphing library.
Global Birth Map
Where in the world are babies being born and how fast?
This interactive, animated map shows the where births are happening across the globe. It doesn’t actually show births in real-time, because data isn’t actually available to do that. However, the map does show the frequency of births that are occurring in different locations across the world. And you can see it in two ways, by country and also geo-referenced to specific locations (along a 1degree grid across the globe). There are many different ways to view this global birth map and these options are laid out in the controls at the top of the map. The scrolling list across the bottom also shows the country of each of the dots on the map.
Instructions
- Speed – change the slider to change the rate at which births show up on the map from real-speed to 25x faster
- Map projection – change the map projection
- Highlight country – an outline around the country when a birth occurs
- Choropleth – Build – as each birth occurs, the background color of the country will slowly change to reflect the number of births in the country
- Choropleth – Show – this option colors all the countries to show the number of births per day that occur in the country
- Dots – Show – this is the main feature that shows where each birth is occurring at the frequency that it does occur.
- Dots – Persist – this feature shows where previous births have occurred and the dots get darker as more births happen in that location.
If you hover (or click on mobile) on a country during the animation, it will display how many births have occurred since the animation stared.
Population distribution data combined with country birthrates
I used data that divided and aggregated the world’s population into 1 degree grid spacing across the globe and I assigned the center of each of these grid locations to a country. Then the country’s annual births (i.e. the country’s population times its birthrate) were distributed across all of the populated locations in each country, weighted by the population distribution (i.e. more populated areas got a greater fraction of the births).
Data Sources and Tools
Population and birthrate data for 2023 was obtained from Wikipedia (Population and birth rates). Population distribution across the globe was obtained from Socioeconomic Data and Applications Center (sedac) at Columbia University.
I used python to process country, population distribution data and parse the data into the probability of a birth at each 1 degree x 1 degree location. Then I used javascript to make random draws and predict the number of births for each map location. D3.js was used to create the map elements and html, css and javascript were used to create the user interface.
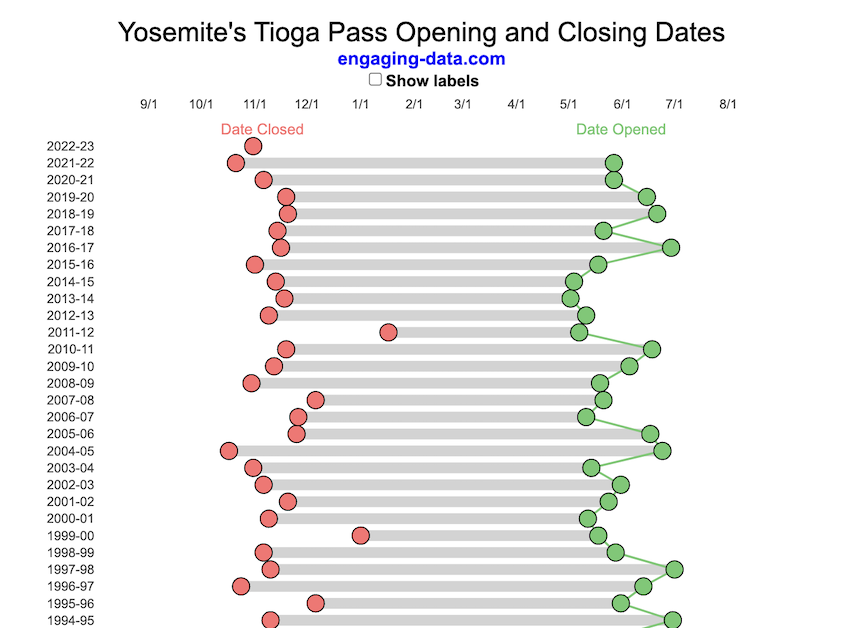
Tioga Pass (Yosemite) Opening Dates
When does Tioga Pass in Yosemite typically open?
The graph shows the closing and opening dates of Tioga pass in Yosemite National Park for each winter season from 1933 to the present. Tioga pass is a mountain pass on State Highway 120 in California’s Sierra Nevada mountain range and one of the entrances to Yosemite NP. The pass itself peaks at 9945 ft above sea level. Each winter it gets a ton of snow, but also with a great deal of variability, which really affects when it can be plowed and the road reopened.
Our family likes to go to Yosemite in June after the kids school lets out and sometimes Hwy 120 and Tioga Pass can often be closed at this time, which limits which areas of the park you can visit. So I often look at data on when the road has opened before and thought it would be a good thing to visualize.
You can toggle the labels on the graph that show the dates of opening and closing as well as the number of days that the pass was closed each winter. Hovering (or clicking) on the circles on the graph will give you a pop up which gives you the exact date.
Data and Tools
The data comes from the US National Park Service for most recent data as well as Mono Basin Clearinghouse for earlier data going back to 1933. Data was organized and compiled in MS Excel. Visualization was done in javascript and specifically the plotly visualization library.
Recent Comments