Navigate the globe to the specified cities eating as many apples as you can
I coded a unique twist on the classic snake game, Snake on a Globe, where your mission is to eat as many apples as you can when given their location and find the best ways to navigate the globe.
The game includes the largest cities in the world and tests your geographical knowledge about country and city locations. Your challenge is to move to the next apple and city in the most efficient manner, moving only along lines of longitude or latitude. But remember you are on a sphere so you can move around the globe in any of four directions: over the poles and east and west.
Instructions
Use the arrow keys (or WASD or IJKL) to move up, down, left and right along the lines of longitude and latitude to try to get to the named city.
The score increases for each apple you eat and there are extra bonus points for the largest cities. For each apple you eat, your body gets longer
The game calculates the least number of steps to move between one apple and the next and your score will start to decline once you exceed this number of steps. The game will remind you that your score is going down because it will be shown in red.
The game ends when your score goes to zero (i.e. you took too long to eat an apple) or if you collide with your own body. One caveat is that you can cross over the poles without hitting your own body if you are on a different line of longitude.
See how many apples you can eat and whether you can get a high score.
Sources and Tools:
The list of cities and their population is from Simplemaps. The game is coded with Three Globe and Three.js, 3D javascript libraries in javascript and HTML and CSS.
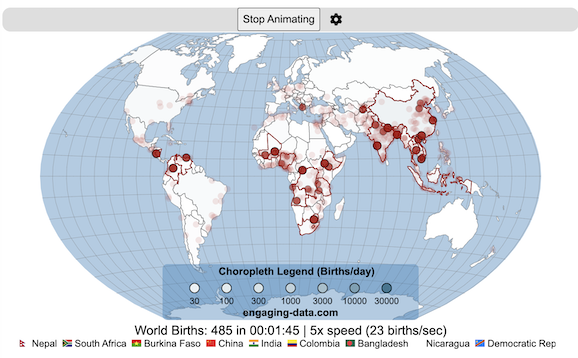
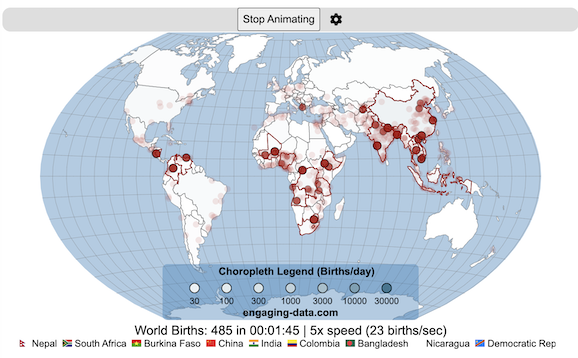
Where in the world are babies being born and how fast?
This interactive, animated map shows the where births are happening across the globe. It doesn’t actually show births in real-time, because data isn’t actually available to do that. However, the map does show the frequency of births that are occurring in different locations across the world. And you can see it in two ways, by country and also geo-referenced to specific locations (along a 1degree grid across the globe). There are many different ways to view this global birth map and these options are laid out in the controls at the top of the map. The scrolling list across the bottom also shows the country of each of the dots on the map.
Instructions
Speed – change the slider to change the rate at which births show up on the map from real-speed to 25x faster
Map projection – change the map projection
Highlight country – an outline around the country when a birth occurs
Choropleth – Build – as each birth occurs, the background color of the country will slowly change to reflect the number of births in the country
Choropleth – Show – this option colors all the countries to show the number of births per day that occur in the country
Dots – Show – this is the main feature that shows where each birth is occurring at the frequency that it does occur.
Dots – Persist – this feature shows where previous births have occurred and the dots get darker as more births happen in that location.
If you hover (or click on mobile) on a country during the animation, it will display how many births have occurred since the animation stared.
Population distribution data combined with country birthrates
I used data that divided and aggregated the world’s population into 1 degree grid spacing across the globe and I assigned the center of each of these grid locations to a country. Then the country’s annual births (i.e. the country’s population times its birthrate) were distributed across all of the populated locations in each country, weighted by the population distribution (i.e. more populated areas got a greater fraction of the births).
I used python to process country, population distribution data and parse the data into the probability of a birth at each 1 degree x 1 degree location. Then I used javascript to make random draws and predict the number of births for each map location. D3.js was used to create the map elements and html, css and javascript were used to create the user interface.
I added a share button (arrow button) that lets you send a graph with specific name. It copies a custom URL to your clipboard which you can paste into a message/tweet/email.
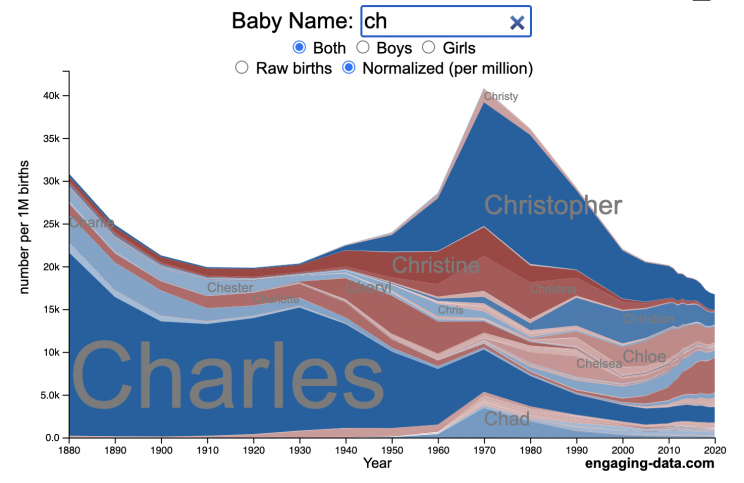
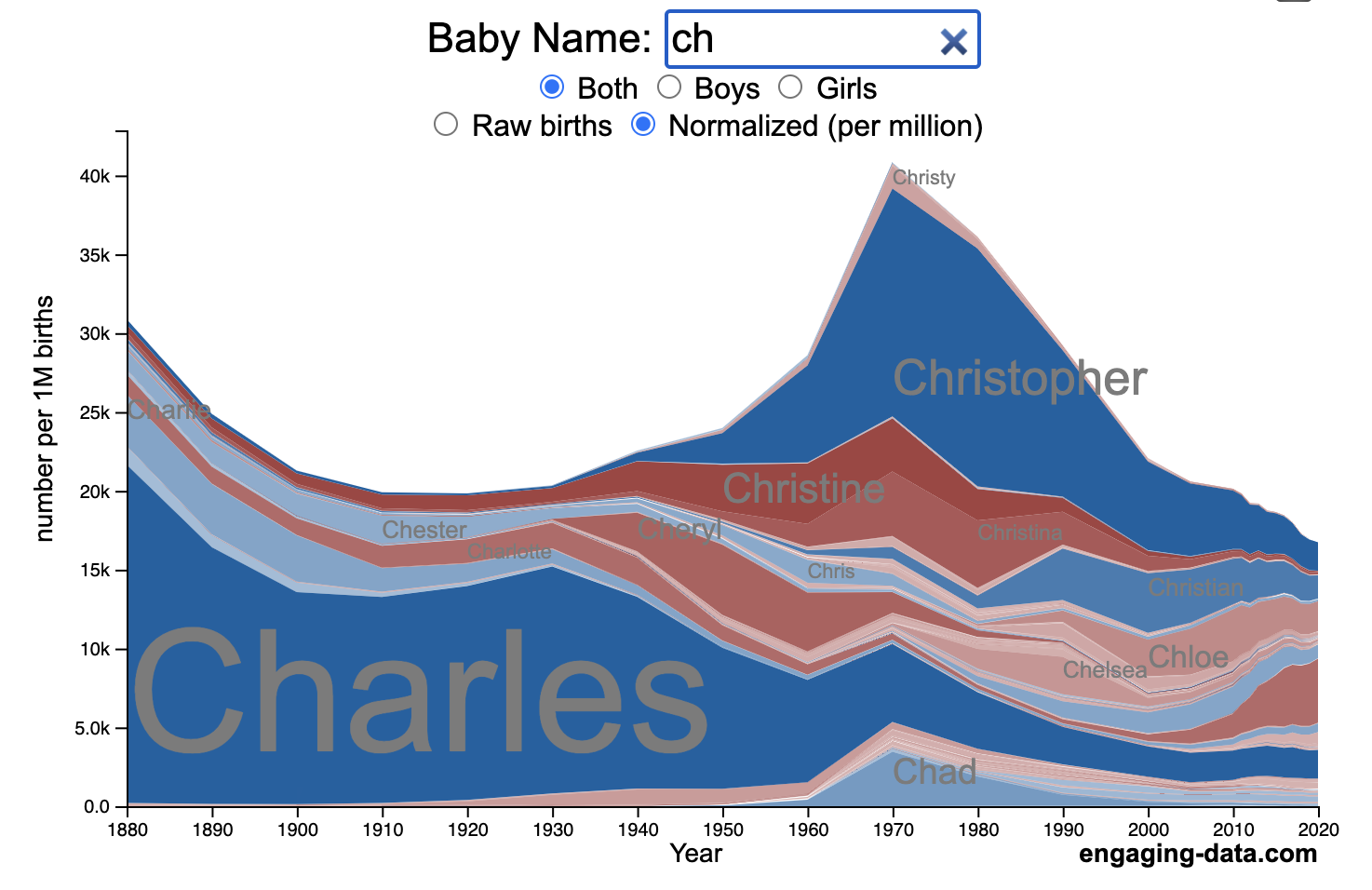
How popular is your name in US history?
Use this visualization to explore statistics about names, specifically the popularity of different names throughout US history (1880 until 2020). This is a useful tool for seeing the rise (and fall) of popularity of names. Look at names that we think of as old-fashioned, and names that are more modern.
Instructions
Start typing a name into the input box above and the visualization will show all the names that begin with those letters. The graph will show the historical popularity of all these names as an area graph.
You can hover (or click on mobile) to bring up a tooltip (popup) that shows you the exact number of births with that name for different years (or decades) and the names rank in that time period.
It’s best used on computer (rather than a mobile or tablet device) so you can see the graph more clearly and also, if you click on a name wedge, it will zoom into names that begin with those letters.
You can select different views, Boy names, Girl names or both, as well as looking at the raw number of births or a normalized popularity that accounts for the differential number of births throughout the period between 1880 and 2020.
If you click the share (arrow) button, it will copy the parameters of the current graph you are looking at and create a custom URL to share with others. It copes the link into your clipboard and your browser’s address (URL) bar.
Isn’t there something out there like this already? Baby Name Wizard and Baby Name Voyager
This visualization is not my original idea, but rather a re-creation of the Baby Name Voyager (from the Baby Name Wizard website) created by Laura Wattenberg. The original visualization disappeared (for some unknown reason) from the web, and I thought it was a shame that we should be deprived of such a fun resource.
It started about a week ago, when I saw on twitter that the Baby Name Wizard website was gone. Here’s the blog post from Laura. I hadn’t used it in probably a decade, but it flashed me back to many years ago well before I got into web programming and dataviz and I remember seeing the Baby Name Voyager and thinking how amazing it was that someone could even make such a thing. Everyone I knew played with it quite a bit when it first came out. It got me thinking that it should still be around and that I could probably make it now with my programming skills and how cool that would be.
So I downloaded the frequency data for Baby Names from the US Social Security Administration and set to work trying to create a stacked area graph of baby names vs time. I started with my go to library for fast dataviz (Plotly.js) but eventually ended up creating the visualization in d3.js which is harder for me, but made it very responsive. I’m not an expert in d3, but know enough that using some similar examples and with lots of googling and stack overflow, I could create what I wanted.
I emailed Laura after creating a sample version, just to make sure it was okay to re-create it as a tribute to the Baby Name Wizard / Voyager and got the okay from her.
All names are from Social Security card applications for births that occurred in the United States after 1879. Note that many people born before 1937 never applied for a Social Security card, so their names are not included in our data.
Name data are tabulated from the “First Name” field of the Social Security Card Application. Hyphens and spaces are removed, thus Julie-Anne, Julie Anne, and Julieanne will be counted as a single entry.
Name data are not edited. For example, the sex associated with a name may be incorrect.
Different spellings of similar names are not combined. For example, the names Caitlin, Caitlyn, Kaitlin, Kaitlyn, Kaitlynn, Katelyn, and Katelynn are considered separate names and each has its own rank.
All data are from a 100% sample of our records on Social Security card applications as of March 2021.
I did notice that there was a significant under-representation of male names in the early data (before 1910) relative to female names. In the normalized data, I set the data for each sex to 500,000 male and 500,000 female births per million total births, instead of the actual data which shows approximately double the number of female names than male names. Not sure why females would have higher rates of social security applications in the early 20th century. Update: A helpful Redditor pointed me to this blog post which explains some of the wonkiness of the early data. The gist of it is that Social Security cards and numbers weren’t really a thing until 1935. Thus the names of births in 1880 are actually 55 year olds who applied for Social Security numbers and since they weren’t mandatory, they don’t include everyone. My correction basically makes the assumption that this data is actually a survey and we got uneven samples from males and female respondents. It’s not perfect (like the later data) but it’s a decent representation of name distribution.
Sources and Tools:
The biggest source of inspiration was of course, Laura Wattenberg’s original Baby Name Explorer.
I downloaded the baby names from the Social Security website. Thanks to Michael W. Shackleford at the SSA for starting their name data reporting. I used a python script to parse and organize the historical data into the proper format my javascript. The visualization is created using HTML, CSS and Javascript code (and the d3.js visualization library) to create interactivity and UI. Curran Kelleher’s area label d3 javascript library was a huge help for adding the names to the graph.
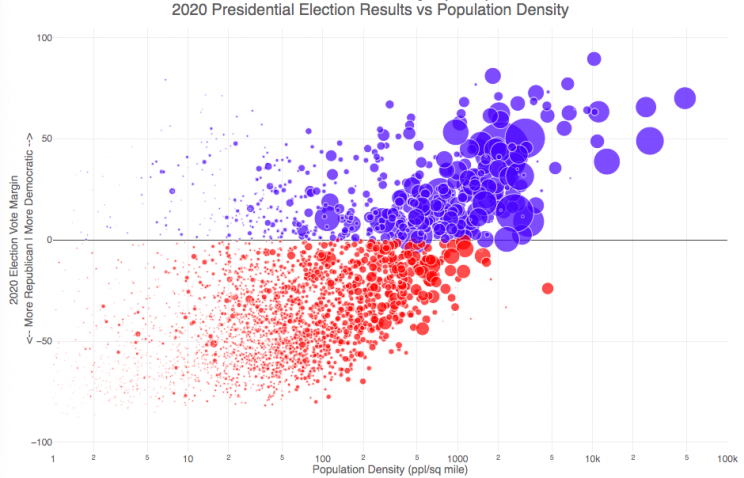
How do 2020 presidential election results correlate with population density?
The visualization I made about county election results and comparing land area to population size was very popular around the time of the 2020 presidential election. As the counties were represented by population, it was clear that democratic-leaning areas on that map tended to grow in size, while republican-leaning areas tended to shrink. This raised the question of exactly how population density correlates with election results.
Hover over (or click on) the bubbles to see information about the county.
It’s clear there is a very strong correlation between the vote margin and population density. Vote margin is the percentage amount that one candidate beat the other candidate by in the county (0% means a tie while 50% means that one candidate got 75% and the other got 25% of the voteshare). Population density is calculated as people per square mile in the county and is shown in the graph on a log scale, where each major grid line is 10 time greater than the previous one. This is done because there is one to two orders of magnitude difference in the densest counties (in New York City) and even moderately dense counties. There are also several counties with population density below 1 person per square mile (several in Alaska because of the size of their counties) but these are excluded from the graph.
Richmond County, NY (i.e. the Borough of Staten Island) is the densest county (17th densest) in the country that Trump won. The densest counties favored Biden quite heavily as he won 45 of the 50 densest counties in the country, which also tend to have a fairly high population.
This second graph is a histogram that specifically categorizes counties into discreet bins by population density. Note that they are on a log scale as well. You can toggle the graph to show the number of counties won by each candidate or the number of votes won in each of the population density bins. The black line shows the percentage of counties (or votes) won by the democratic candidate (Joe Biden) in each of those bins.
Hover over (or click on) the bars to see information about each county bin.
It’s pretty clear in these graphs that low population density areas clearly favor the republican while the denser areas favor the democrat.
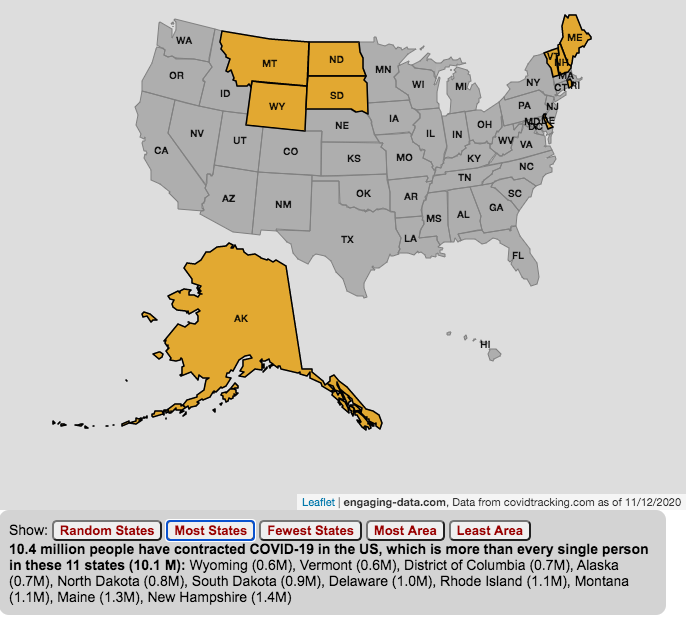
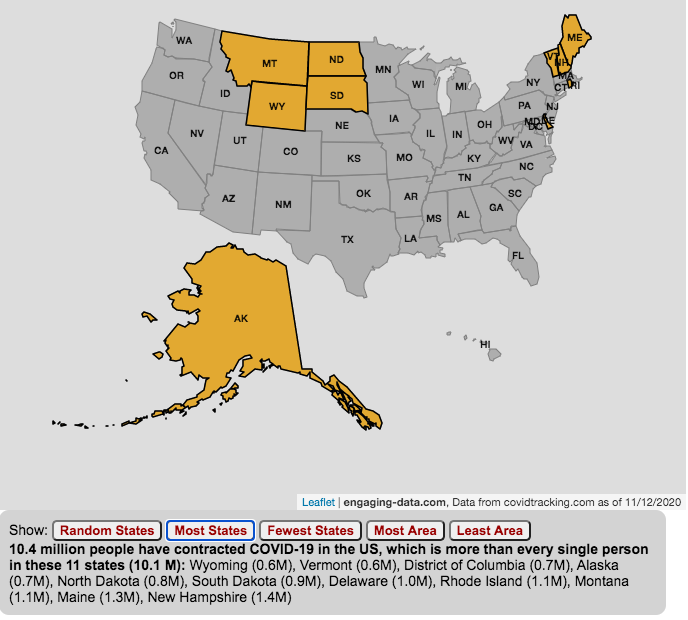
The number of US coronavirus cases is equal to the population of several states put together.
click on the buttons below to see a new set of states.
The number of Americans who have contracted the Coronavirus keeps going up with little indication of slowing down. This is an amazingly large number of cases is the highest in the world and I wanted to visualize how many people this actually is.
While the number of US COVID-19 cases is very large, comparing these number to the size of the populations in several states helps to provide more context. The visualization shows a random collection of states whose total population is equal to the latest coronavirus numbers. If you click the button you can see a different set of states that have a population equal to the current number of coronavirus cases.
The graph is updated daily using data from covidtracking.com. It’s important to note that the number of people with COVID-19 is an underestimate as many coronavirus cases are asymptomatic (i.e. people don’t get sick or show any symptoms) and the positivity rate of tests is quite high.
Stay safe out there: stay away from people and wear your mask!
Each state has two senators in the Senate, even though there is a great disparity in the populations of the states. This was a compromise that the framers of the Constitution dealt with in creating the framework of the US government. While the US House of Representatives is based on proportional representation, the Senate was designed to have two senators per state regardless of population. This leads to some interesting variations in the number of votes that some senators get relative to other senators (and how many people they represent).
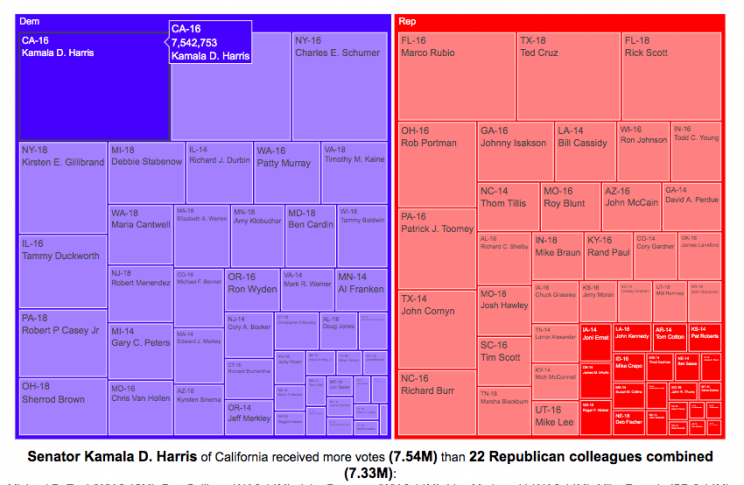
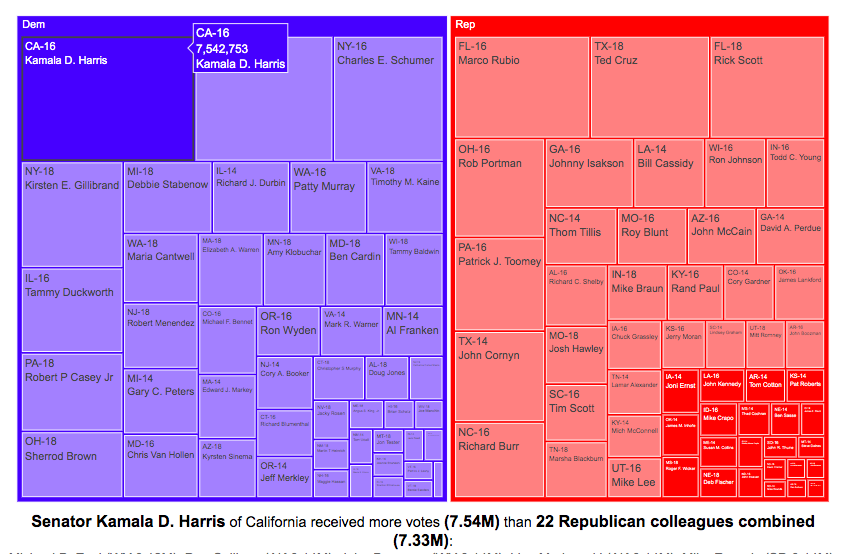
Graph of Total Votes for Each Current Senator (2014, 2016 and 2018)
This graph is called a treemap and shows the total number of votes cast for the winner of each senate race of the current sitting senators. They are shown in order from largest to smallest vote totals, where the area of the rectangle is proportional to the number of votes. The treemap can be organized by party if desired. This graph does not show the number of votes that their opponents got.
If you hover over (click, on mobile) one of the boxes in the treemap, you can compare the number of votes received by that senator to the number of senators that received the same number of votes combined. This helps highlight the disparities in the representation of voters in large states in the Senate relative to that of voters in states with low populations.
For example, Kamala Harris, Democratic senator of my home state of California, received 7.5 million votes when she won her senate race in 2016. This large number of votes is larger than the combined votes for 22 of her Republican colleagues in small states. This is even more impressive since, as noted before, she ran against another Democrat Loretta Sanchez, in the election.
Note that some of the recently elected senators shown in the table are no longer serving in the Senate:
John McCain’s seat is currently held by Martha McSally
Johnny Isakson’s seat is currently held by Kelly Loeffler
Because of the large variation in population sizes and a tendency for more populous states to vote for democrats, Democratic Senators received many more votes in their elections than their Republican colleagues did, despite having fewer numbers. The 47 Democratic (and Independent) senators received a total of 67.5 million votes while the 53 Republican senators received 59.5 million votes.
Graph of Margin of Victory over Opposing Party for Each Current Senator (2014, 2016 and 2018)
This graph shows a slightly different set of data. Instead of total votes for the winning candidate, it shows the vote margin (i.e. the number of votes the winner received vs the opponent of a different party). The reason I specify it this way is that the two Democratic California senators defeated other democrats to win their elections (i.e. no republican was on the ballot in the general election because no republican got enough votes in the primary). This comparison is interesting because not only do some senators receive very few votes (because they live in small states), but they may only win by a small margin over their opponents. Comparing margins of victory, shows how few votes it would take to “flip” a Senate seat between the two parties.
If you take Kamala Harris’s margin of victory over Republicans to be her vote total (7.5 million votes) since there was no Republican running against her, her margin of victory is greater than the margin of victory of 43 of her Republican Senate colleagues combined.



Recent Comments