Posts for Tag: data
Compound Interest and Stock Returns Calculator
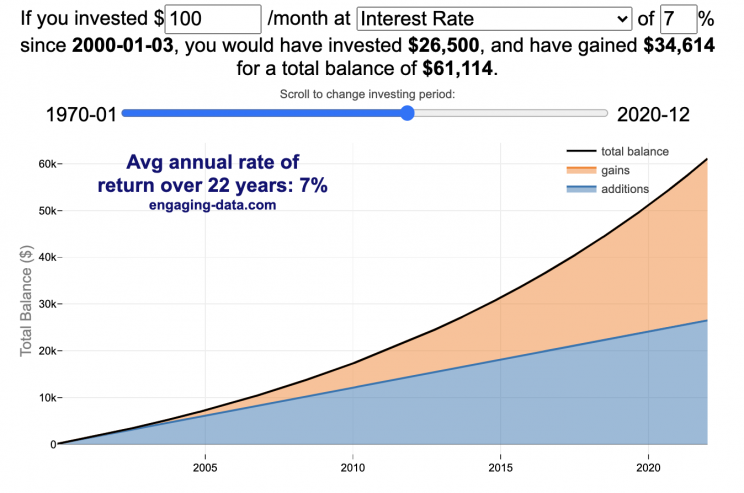
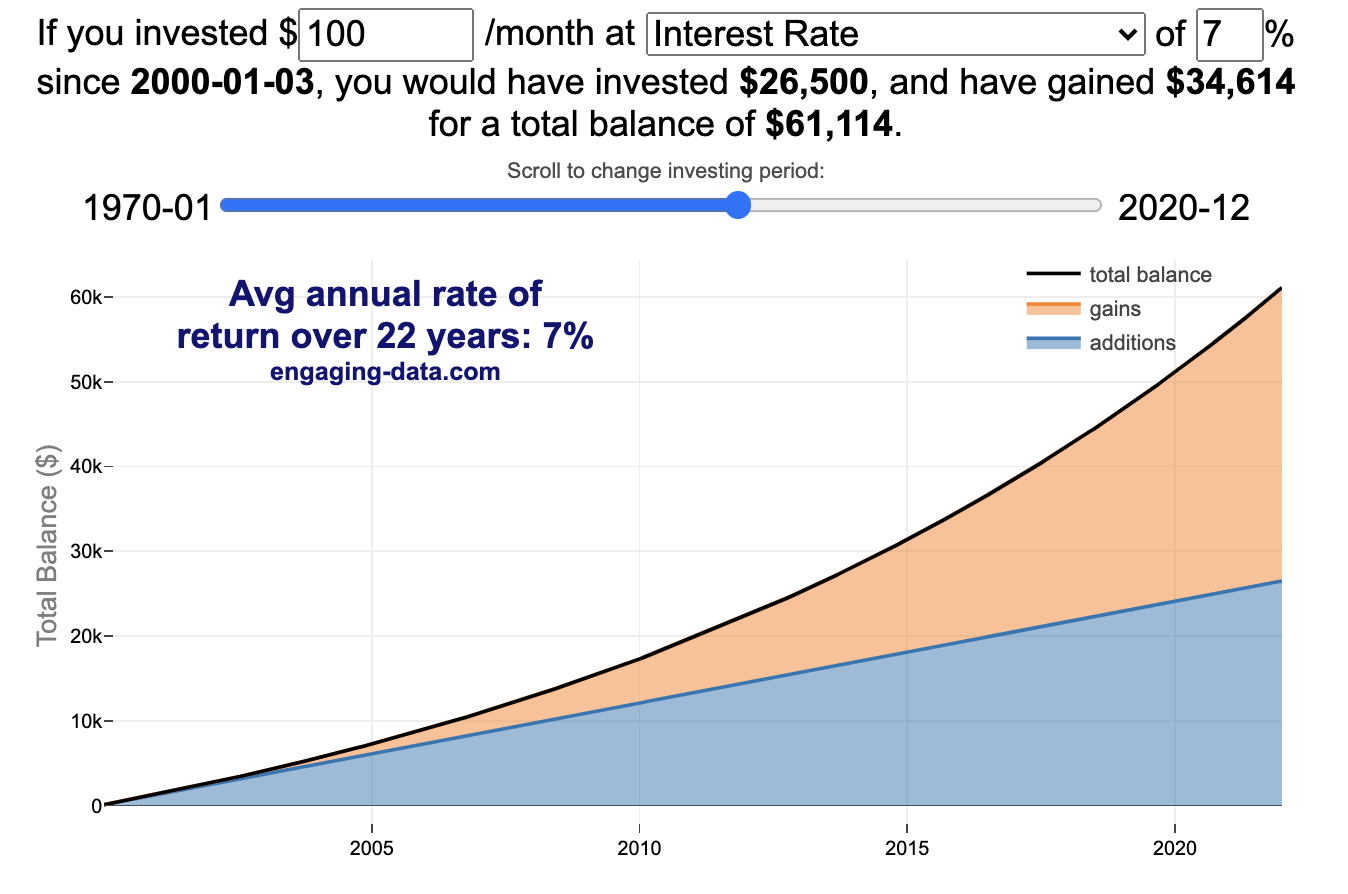
Calculate returns on regular, periodic investments
This calculator lets you visualize the value of investing regularly. It lets you calculate the compounding from a simple interest rate or looking at specific returns from the stock market indexes or a few different individual stocks.
Instructions
- Enter the amount of money to be invested monthly
- Choose to use an interest rate (and enter a specific rate) or
- Choose a stock market index or individual stock
- Use the slider to change the initial starting date of your periodic investments – You can go as far back as 1970 or the IPO date of the stock if it is later than that.
- Use the “Generate URL to Share” button to create a special URL with the specific parameters of your choice to share with others – the URL will appear in your browser’s address bar.
You can hover over the graph to see the split between the money you invested and the gains from the investment. In most cases (unless returns are very high), initially the investments are the large majority of the total balance, but over time the gains compound and eventually, it is those gains rather than the initial investments that become the majority of the total.
Some of the tech stocks included in the dropdown list have very high annualized returns and thus the gains quickly overtake the additions as the dominant component of the balance and you can make a great deal of money fairly quickly.
It becomes clearer as you move the slider around, that longer investing time periods are the key to increasing your balance, so building financial prosperity through investing is generally more of a marathon and not really a sprint. However, if you invest in individual stocks and pick a good one, you can speed up that process, though it’s not necessarily the most advisable way to proceed. Lots of people underperform the market (i.e. index funds) or even lose money by trying to pick big winners.
Understanding the Calculations
Calculating compound returns is relatively easy and is just a matter of consecutively multiplying the return. If the return is 7% for 5 years, that is equal to multiplying 1.07 five times, i.e. 1.075 = 1.402 (or a 40.2% gain).
In this case, we are adding additional investments each month but the idea is the same. Take the amount of money (or value of shares) and multiply by the return (>1 if positive or <1 for negative returns) after each period of the analysis.
Sources and Tools:
Stock and index monthly data is downloaded from Yahoo! finance is downloaded regularly using a python script.
The graph is created using the open-source Plotly javascript visualization library, as well as HTML, CSS and Javascript code to create interactivity and UI.
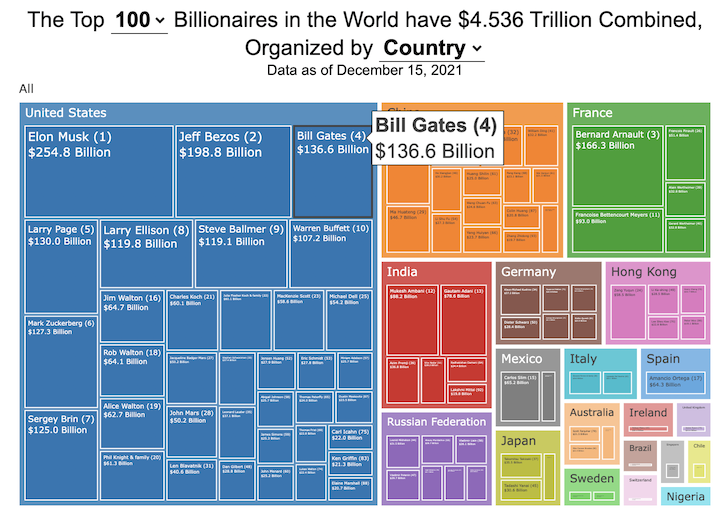
How much wealth do the world’s richest billionaires have?
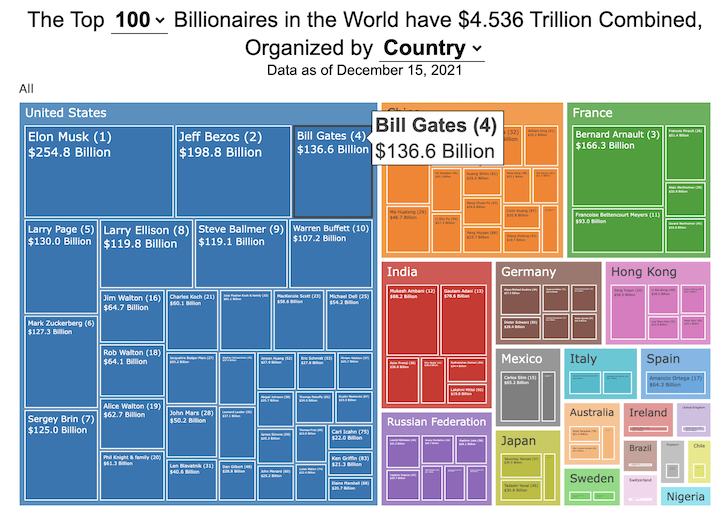
This dataviz compares how rich the world’s top billionaires are, showing their wealth as a treemap. The treemap is used to show the relative size of their wealth as boxes and is organized in order from largest to smallest.
User controls let you change the number of billionaires shown on the graph as well as group each person by their country or industry. If you group by country or industry, you can also click on a specific grouping to isolate that group and zoom in to see the contents more clearly. Hovering over each of the boxes (especially the smaller ones) will give you a popup that lets you see their name, ranking and net worth more clearly.
The popup shows how much total wealth the top billionaires control and for context compare it to the wealth of a certain number of households in the US. The comparison isn’t ideal as many of the billionaires are not from the US, but I think it still provides a useful point of comparison.
This visualization uses the same data that I needed in order to create my “How Rich is Elon Musk?” visualization. Since I had all this data, I figured I could crank out another related graph.
Sources and Tools:
Data from Bloomberg’s Billionaire’s index is downloaded regularly using a python script. Data on US household net worth is from DQYDJ’s net worth percentile calculator.
The treemap is created using the open-source Plotly javascript visualization library, as well as HTML, CSS and Javascript code to create interactivity and UI.
How Rich is Elon Musk? – Visualization of Extreme Wealth
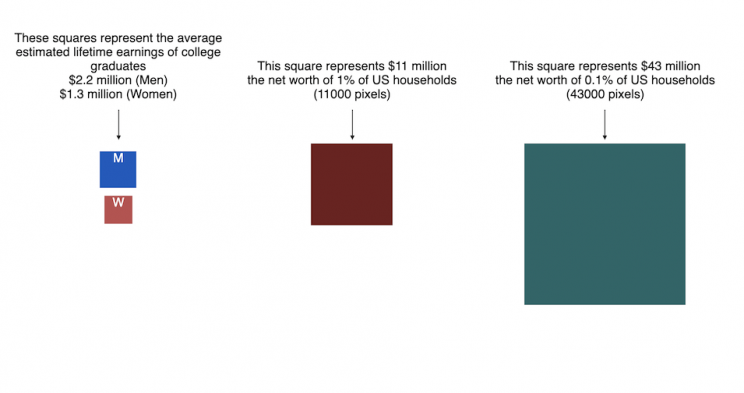
See related visualization: How much wealth do the world’s richest billionaires have?
Visualizing Elon Musk net worth in 2024
This visualization attempts to represent how much money Elon Musk, the richest person in the world, has. It gives context on this extreme amount of wealth by showing other very large sums of money that are somehow less than his net worth.
Each pixel on the screen represents a very modest amount of money (from $ 500 to $ 4000). As you scroll to the right, you will start to understand how incredibly large one billion dollars is, let alone hundreds of billions. You can change the amount of scrolling needed to get to the end of the visualization by selecting the amount represented by one pixel in the drop down menu.
This visualization was inspired heavily by a similar visualization made by Matt Korostoff for Jeff Bezos (when he was the richest person in the world) called “Wealth shown to scale”.
If you have any ideas about other items that could be added to the money chart, please leave them in the comments, and I will see if I can add it.
Mega-billionaires such as Musk or Jeff Bezos are not just extremely rich, the wealth they possess is unimaginably large. There are some extremely rich folks shown in the visualization who can buy pretty much whatever they could ever possibly need and yet their wealth is closer to that of the average person than they are to that of Elon Musk.
Sources and Tools:
The full list of data sources for the various money amounts are listed below. Most data is from 2021 though networth data for billionaires is updated regularly. The visualization was made using HTML, CSS and Javascript code to create interactivity and UI. Data from Bloomberg’s Billionaire’s index , which is the source of Musk’s (and others) estimated wealth, is updated regularly.
Full List of Data Sources:
- Cost of a supertanker’s worth of oil (at $70/barrel): https://en.wikipedia.org/wiki/Oil_tanker
- Cost of a Boeing 777-200ER Airplane: https://en.wikipedia.org/wiki/Boeing_777
- Lebron James and Cristiano Ronaldo Net Worth: https://wealthygorilla.com/top-20-richest-athletes-world/
- Tiger Woods Net Worth: https://wealthygorilla.com/top-20-richest-athletes-world/
- It’s alot of money, but we’ve still got a long way to go:
- Cost of building the Burj Khalifa (world’s tallest building in Dubai): https://en.wikipedia.org/wiki/Burj_Khalifa
- Total Ad Revenue for CNN, Fox News and MSNBC: https://www.pewresearch.org/journalism/fact-sheet/cable-news/
- Ophrah Winfrey Net Worth: https://www.celebritynetworth.com/richest-celebrities/actors/oprah-net-worth/
- Tuition for all 280,000 University of California Students: https://www.ucop.edu/operating-budget/_files/rbudget/2021-22-budget-detail.pdf
- One 40-Foot Shipping Container Full of $100 Bills: self-calculation
- Net Worth of Bottom 33% of Americans: https://dqydj.com/average-median-top-net-worth-percentiles/
- George Lucas Net Worth: https://www.bloomberg.com/billionaires/
- Cost of 2020 Tokyo Olympics: https://www.usnews.com/news/business/articles/2021-08-06/tokyo-olympics-cost-154-billion-what-else-could-that-buy
- Annual Budget of the US Department of Energy: https://en.wikipedia.org/wiki/United_States_Department_of_Energy
- Worldwide Box Office Revenue for Marvel Cinematic Universe (2008-2021): https://www.the-numbers.com/movies/franchise/Marvel-Cinematic-Universe#tab=summary
- Total Amount Spent of Gasoline in the State of Texas in one year: https://www.eia.gov/state/seds/data.php?incfile=/state/seds/sep_fuel/html/fuel_mg.html&sid=US
- Size of Harvard University’s Endowment: https://www.thecrimson.com/article/2021/10/15/endowment-returns-soar-2021/
- Annual Budget of the US Department of Transportation: https://en.wikipedia.org/wiki/United_States_Department_of_Transportation
- Total Gross State Product of Hawaii in 2021: https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States_by_GDP
- Warren Buffet Net Worth: https://www.bloomberg.com/billionaires/
- State of Texas Operating Budget: https://en.wikipedia.org/wiki/List_of_U.S._state_budgets
- Total Value of all National Football League (NFL) Teams: https://www.profootballnetwork.com/nfl-franchise-values/
- Total Annual Income of 2 Million Residents of Silicon Valley (San Jose-Sunnyvale-Santa Clara CA Metro Area): https://censusreporter.org/profiles/31000US41940-san-jose-sunnyvale-santa-clara-ca-metro-area/
- Total Dollar Value of All US Agricultural Production: https://www.ers.usda.gov/data-products/ag-and-food-statistics-charting-the-essentials/ag-and-food-sectors-and-the-economy/
- Bill Gates Net Worth: https://www.bloomberg.com/billionaires/
- Total Tesla Revenue Since Founding (2008-2021): https://www.statista.com/statistics/272120/revenue-of-tesla/
- Annual Advertising Revenue for Google: https://www.cnbc.com/2021/05/18/how-does-google-make-money-advertising-business-breakdown-.html
- Total Amount Spent on US Residential Electricity In A Year: https://www.eia.gov/state/seds/data.php?incfile=/state/seds/sep_fuel/html/fuel_pr_es.html&sid=US
- Jeff Bezos Net Worth: https://www.bloomberg.com/billionaires/
- Annual Federal Taxes paid in Florida: https://en.wikipedia.org/wiki/Federal_tax_revenue_by_state
- Global Electric Vehicle Market Size in 2020: https://www.globenewswire.com/en/news-release/2021/09/06/2291730/0/en/Electric-Vehicle-Market-Size-Is-Anticipated-to-Grow-USD-1-318-22-Billion-in-2028-at-a-CAGR-of-24-3.html
- Value (i.e. Market Capitalization) of Walt Disney Company: https://www.google.com/finance/quote/DIS:NYSE
- Annual Revenue of Toyota Motor Corporation: https://money.cnn.com/quote/financials/financials.html?symb=TM
- Annual Health Care Expenditures for the entire State of California: https://www.kff.org/other/state-indicator/health-care-expenditures-by-state-of-residence-in-millions/?currentTimeframe=0&sortModel=%7B%22colId%22:%22Location%22,%22sort%22:%22asc%22%7D
- Total Annual Income for 100,000 Average US Households: https://www.census.gov/library/publications/2021/demo/p60-273.html
- Cost of one Gerald Ford Class Aircraft Carrier: https://en.wikipedia.org/wiki/Gerald_R._Ford-class_aircraft_carrier
- Cost to Build California High Speed Rail System: https://en.wikipedia.org/wiki/California_High-Speed_Rail
- Inflation Adjusted Cost of NASA’s Apollo Program: https://www.forbes.com/sites/alexknapp/2019/07/20/apollo-11-facts-figures-business/
- Total Annual Housing and Utilities Expenditures For All 6.6 Million Households in Los Angeles Metro Area: https://www.bls.gov/cex/tables/geographic/mean/cu-msa-west-2-year-average-2020.pdf
- Annual Amount Spent on the Purchase of iPhones: https://www.businessofapps.com/data/apple-statistics/
- Annual Aggregate Salaries of US Workers in 2023 (various occupations): BLS Website: https://www.bls.gov/oes/current/oes_nat.htm
- Consumer Purchases: BEA Website: https://apps.bea.gov/
- Welfare Spending: Pew Research: https://www.pewresearch.org/short-reads/2023/07/19/what-the-data-says-about-food-stamps-in-the-u-s/
- Market Cap or Revenue for large companies : Stock Analysis: https://stockanalysis.com/list/sp-500-stocks/
- Elon Musk Net Worth: https://www.bloomberg.com/billionaires/
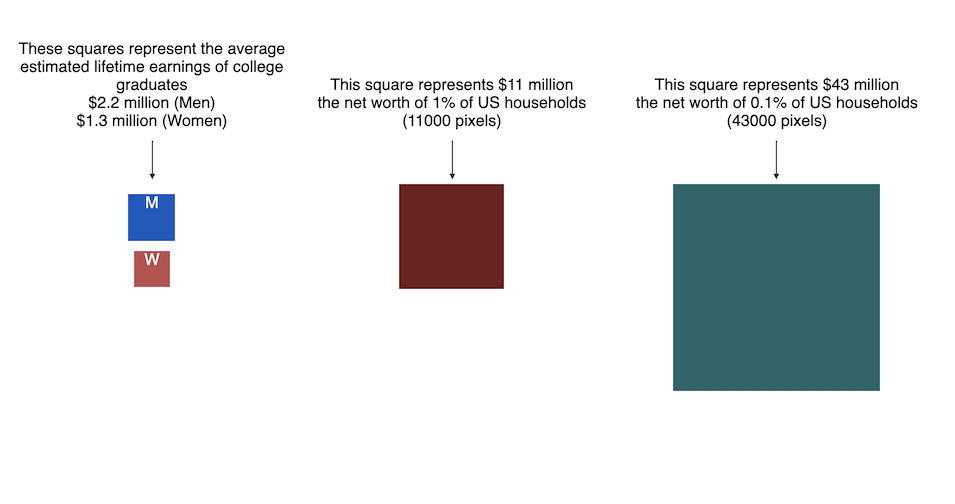
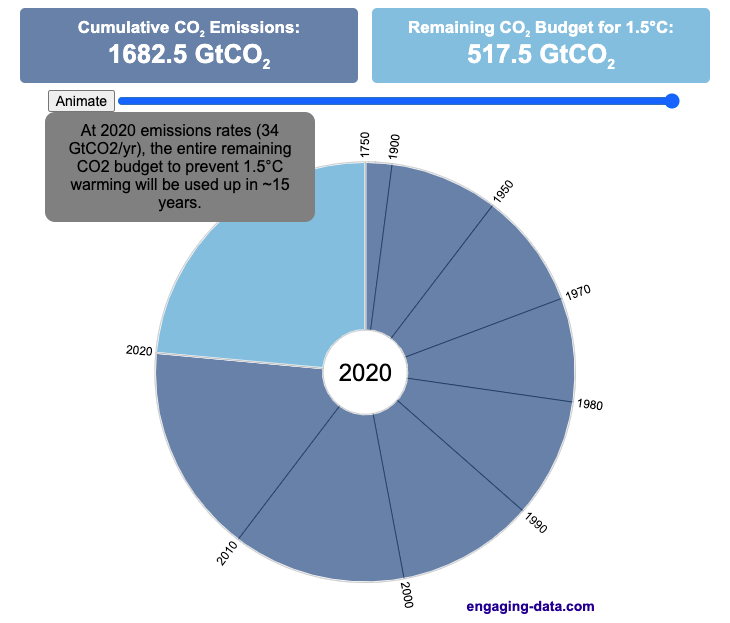
Using up our carbon budget
How much more CO2 can we emit if we want to keep the global temperature rise below 1.5°C or 2°C?
Every bit of CO2 we release is one step closer to using up our carbon budget.
Click on the animate button (or use the slider) to see how we have used up our carbon budget to limit global warming to 1.5°C or 2°C.
Climate change is the result of greenhouse gases such as CO2 and methane from human activities. The amount of CO2 and other greenhouse gases in the atmosphere determines how much of the incoming solar radiation is trapped as heat. Since CO2 is the most common greenhouse gas and very long lived in the atmosphere, there’s a good correlation between the total amount of human CO2 emissions and the amount of warming that the earth will experience. This leads to the concept of a carbon budget.
What is the carbon budget?
For every ton of CO2 that is emitted into the atmosphere about half a ton becomes part of the atmosphere for the long term, assuming there’s no massive new program to remove CO2 from the atmosphere. And there’s a direct correlation between the atmospheric concentration of CO2 and the earth’s temperature. Scientists tend to look at milestones of 2°C or 1.5°C when thinking about potential future warming. There is some uncertainty, but the total amount of human CO2 emissions that will lead to a 1.5°C warming from pre-industrial levels is around 2200 billion metric tonnes of CO2 plus or minus a few hundred billion tons (or 460 billion metric tonnes from 2020). This unit is also written as GtCO2 or gigatonnes of CO2. The values for the budget for 2°C warming are 1310 GtCO2 from 2020 or 2993 GtCO2 from pre-industrial levels.
Shown below is a graph from the Carbon Brief that shows the uncertainty in estimates for the remaining carbon budget (from 2018) before having a 50% chance of exceeding 1.5°C warming. As you can see there’s a fairly large range.
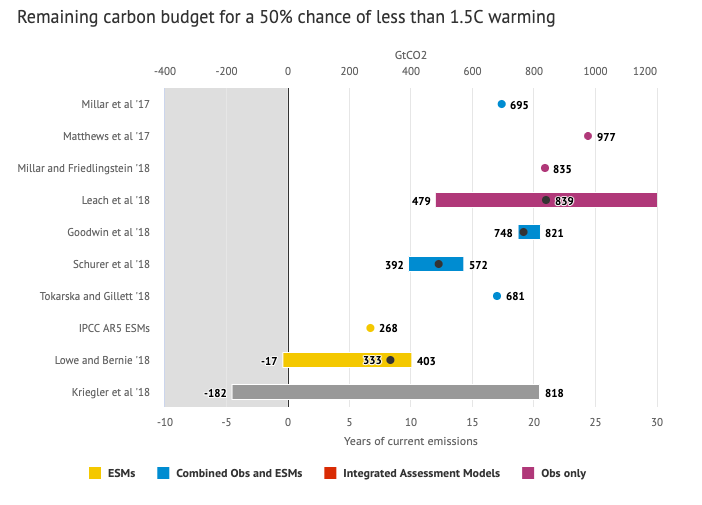
Update: The article’s author Zeke Hausfather pointed me to an updated article with newer IPCC estimates for the carbon budget of these two warming milestones. I have updated the code to account for these two new values.
What may happen at 1.5 degrees of warming?
1.5°C (2.7°F) doesn’t sound like alot, but there are some pretty serious potential consequences that we’ll be dealing with. These include increasing the amount or frequency of the following:
- extreme heatwaves
- droughts
- extreme storms and precipitation events
- loss of wildlife and biodiversity
- sea level rise
- and impacts of human health
This NASA article has much more info on the specific issues related to this temperature rise. Ideally we’d keep warming to under 1.5°C but it looks likely that we may exceed 2°C unless we take fairly dramatic action to reduce or CO2 emissions from fossil fuel combustion and use cleaner/lower-carbon sources of energy, like renewables and nuclear power.
From 1750 to 2020, humans have emitted approximately 1683 GtCO2. The IPCC estimates that 460 GtCO2 would put us at 1.5°C warming and 1310 GtCO2 would put us at 2°C warming. These values give us an estimated total carbon budget of 2143 GtCO2 for 1.5°C and 2993 GtCO2 for 2°C warming.
You can really see how we are getting close to using up all of our 1.5°C carbon budget and the speed at which we are using it up, especially in the last few decades.
Sources and Tools:
Annual emissions data is from the Global Carbon Project. The visualization was made using the plotly.js open source graphing library and HTML/CSS/Javascript code for the interactivity and UI.
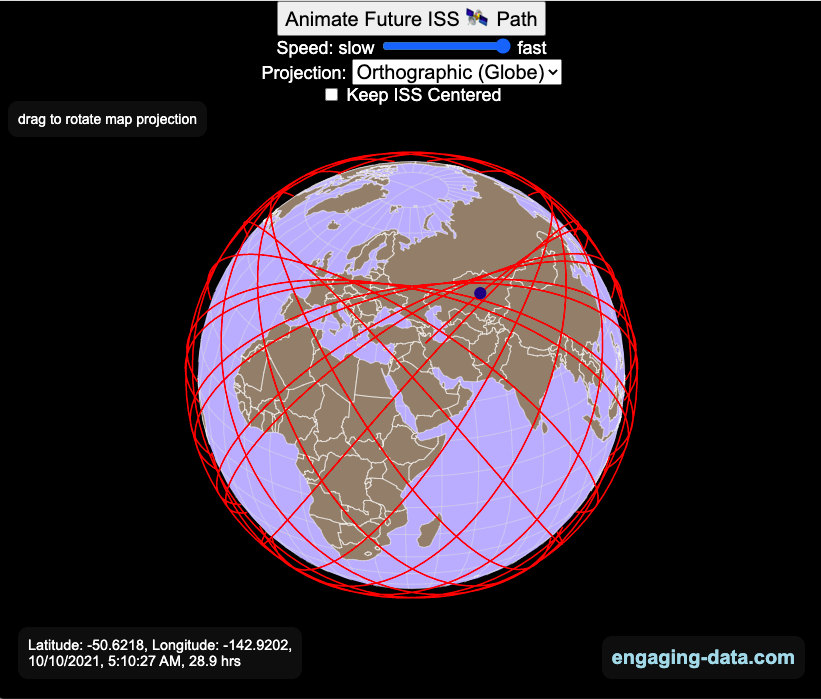
Visualizing the Orbit of the International Space Station (ISS)
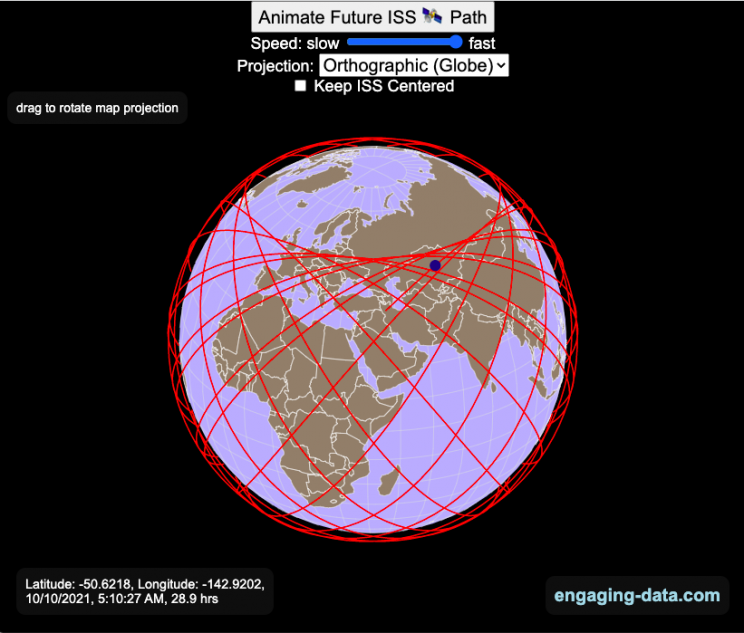
Where is the International Space Station currently? And what pattern does it make as it orbits around the Earth?
This visualization shows the current location of the International Space Station (ISS), actually the point above the Earth that the station is closest to. It is approximately 260 miles (420 km) above the Earth’s surface The station began construction in 1998 and had its first long term residents in 2000.
The visualization can also show the animated future orbital path of the ISS using ephemeris calculations, which makes a nice, cool pattern over an approximately 3.9 day cycle, where it starts to repeat. The animation allows you to view the orbital patterns on the globe (orthographic projection) or a mercator or equirectangular projection.
One of the cooler features is to drag and rotate the globe view while the orbital paths are being drawn. You can also adjust the speed of the orbit as well as keep the ISS centered in your view while the globe spins around underneath it. If you select the “rotate earth” checkbox, it becomes apparent that the ISS is in a circular orbit around the earth and that the pattern being made is simply a function of the earth’s rotation underneath the orbit.
This visualization only shows the approximate location of the ISS as there are several confounding factors that are not represented here. The speed of the ISS changes somewhat over time as the station experiences a small amount of atmospheric drag, which slows the station over time. But it still goes over 7000 meters per second or about 17000 miles per hour. As it slows, its orbit decays so it falls closer to earth and it experiences even more atmospheric drag. Occasionally, the station is boosted up to a higher orbit to counteract this decay. Secondly the earth is not a perfect sphere and this also causes the calculations to be only approximately correct.
Some other cool facts about the International Space Station:
- the angle the orbit makes relative to the equator is 51.6 degrees (i.e. this means the highest and lowest latitudes it will reach are 51.6 degrees North and South and doesn’t orbit over the poles
- the circular orbit around the earth makes a sin wave pattern on 2D map projections (shown on the mercator and equirectangular projections
- one orbit takes about 90 minutes. This means there are approximately 16 orbits per day and astronauts aboard the ISS will see 16 sunrises and sunsets
Other cool space-related orbital art can be seen at the inner planet spirographs.
Here are a couple of images showing the final pattern made by the ISS on different map projections.
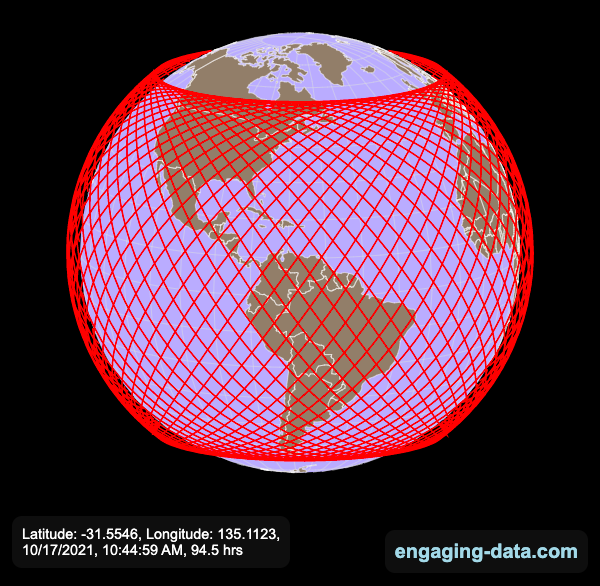
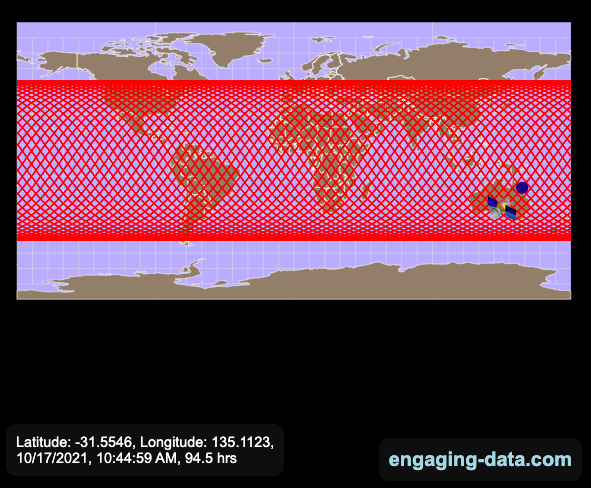
Sources and Tools:
I used the satellite.js javascript package and the ISS TLE file to calculate the position of the ISS.
The visualization was made using the d3.js open source graphing library and HTML/CSS/Javascript code for the interactivity and UI.
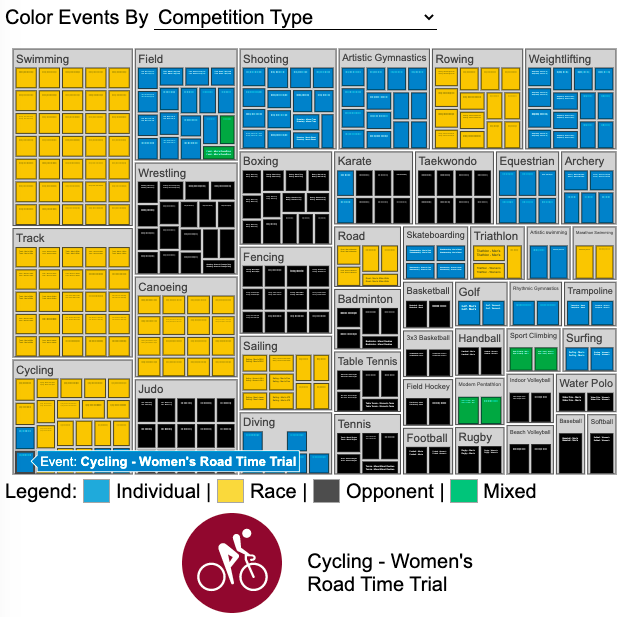
Visualizing Olympic Sports
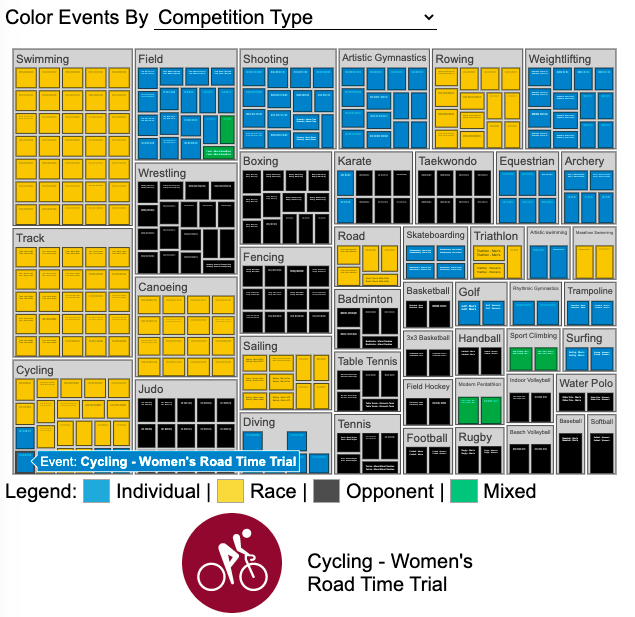
See all 339 Olympic Events in the Tokyo 2020/2021 Olympics
It had always seemed like the most decorated US Olympians tended to be swimmers, so I wanted to see how all the various events are distributed across the different types of sports. Each sport (like swimming) has a number of individual events and are show in a treemap as a collection of boxes. And indeed swimming does have the most individual events of any of the sports in the 2020/2021 Olympics.
I also wanted to see how you can categorize the different Olympic events, so I looked at several different dimensions, which are color coded:
- Athlete Gender – Events are categorized into Men’s, Women’s, Mixed and Open Events. Mixed is when a specified number of Men and Women are in an event (i.e. one man and one woman) while Open events can be either Men or Women.
- Team vs Individual – Events are categorized into whether the competitors are individuals or a team (more than one individual)
- Competition Type – Events are categorized into the type of competition, such as a Race (competitors are performing simultaneously to see who finishes first), Individual (where the competitor performs the event by themselves), Opponent (where the competition is one opponent vs another) or Mixed (where there’s some combination of these types)
- How winner are Determined – Events are categorized by the type of scoring: Timed (including all races), Judged, Scored (either in ball sports such as soccer or tennis, or in fighting sports like boxing and wrestling), Completion (where each competitor attempts to complete a jump or lift and the winner is the one who can complete the highest level), Distance (jumping and throwing events) and Hybrid (a combination of these types).
The sports with the largest number of individual events is swimming, then track, cycling, and field. Some the fighting sports have many individual events but they are all exclusive categories (i.e. you can’t compete in two different boxing or wrestling events).
Sources and Tools:
I grabbed a list of Olympic sports from Wikipedia and manually coded the information about gender, competition type and other factors. The visualization uses the plotly.js open source graphing library and HTML/CSS/Javascript code for the interactivity and UI.
Compound Interest and Stock Returns Calculator
Calculate returns on regular, periodic investments
This calculator lets you visualize the value of investing regularly. It lets you calculate the compounding from a simple interest rate or looking at specific returns from the stock market indexes or a few different individual stocks.
Instructions
- Enter the amount of money to be invested monthly
- Choose to use an interest rate (and enter a specific rate) or
- Choose a stock market index or individual stock
- Use the slider to change the initial starting date of your periodic investments – You can go as far back as 1970 or the IPO date of the stock if it is later than that.
- Use the “Generate URL to Share” button to create a special URL with the specific parameters of your choice to share with others – the URL will appear in your browser’s address bar.
You can hover over the graph to see the split between the money you invested and the gains from the investment. In most cases (unless returns are very high), initially the investments are the large majority of the total balance, but over time the gains compound and eventually, it is those gains rather than the initial investments that become the majority of the total.
Some of the tech stocks included in the dropdown list have very high annualized returns and thus the gains quickly overtake the additions as the dominant component of the balance and you can make a great deal of money fairly quickly.
It becomes clearer as you move the slider around, that longer investing time periods are the key to increasing your balance, so building financial prosperity through investing is generally more of a marathon and not really a sprint. However, if you invest in individual stocks and pick a good one, you can speed up that process, though it’s not necessarily the most advisable way to proceed. Lots of people underperform the market (i.e. index funds) or even lose money by trying to pick big winners.
Understanding the Calculations
Calculating compound returns is relatively easy and is just a matter of consecutively multiplying the return. If the return is 7% for 5 years, that is equal to multiplying 1.07 five times, i.e. 1.075 = 1.402 (or a 40.2% gain).
In this case, we are adding additional investments each month but the idea is the same. Take the amount of money (or value of shares) and multiply by the return (>1 if positive or <1 for negative returns) after each period of the analysis.
Sources and Tools:
Stock and index monthly data is downloaded from Yahoo! finance is downloaded regularly using a python script.
The graph is created using the open-source Plotly javascript visualization library, as well as HTML, CSS and Javascript code to create interactivity and UI.
How much wealth do the world’s richest billionaires have?
This dataviz compares how rich the world’s top billionaires are, showing their wealth as a treemap. The treemap is used to show the relative size of their wealth as boxes and is organized in order from largest to smallest.
User controls let you change the number of billionaires shown on the graph as well as group each person by their country or industry. If you group by country or industry, you can also click on a specific grouping to isolate that group and zoom in to see the contents more clearly. Hovering over each of the boxes (especially the smaller ones) will give you a popup that lets you see their name, ranking and net worth more clearly.
The popup shows how much total wealth the top billionaires control and for context compare it to the wealth of a certain number of households in the US. The comparison isn’t ideal as many of the billionaires are not from the US, but I think it still provides a useful point of comparison.
This visualization uses the same data that I needed in order to create my “How Rich is Elon Musk?” visualization. Since I had all this data, I figured I could crank out another related graph.
Sources and Tools:
Data from Bloomberg’s Billionaire’s index is downloaded regularly using a python script. Data on US household net worth is from DQYDJ’s net worth percentile calculator.
The treemap is created using the open-source Plotly javascript visualization library, as well as HTML, CSS and Javascript code to create interactivity and UI.
How Rich is Elon Musk? – Visualization of Extreme Wealth
See related visualization: How much wealth do the world’s richest billionaires have?
Visualizing Elon Musk net worth in 2024
This visualization attempts to represent how much money Elon Musk, the richest person in the world, has. It gives context on this extreme amount of wealth by showing other very large sums of money that are somehow less than his net worth.
Each pixel on the screen represents a very modest amount of money (from
This visualization was inspired heavily by a similar visualization made by Matt Korostoff for Jeff Bezos (when he was the richest person in the world) called “Wealth shown to scale”.
If you have any ideas about other items that could be added to the money chart, please leave them in the comments, and I will see if I can add it.
Mega-billionaires such as Musk or Jeff Bezos are not just extremely rich, the wealth they possess is unimaginably large. There are some extremely rich folks shown in the visualization who can buy pretty much whatever they could ever possibly need and yet their wealth is closer to that of the average person than they are to that of Elon Musk.
Sources and Tools:
The full list of data sources for the various money amounts are listed below. Most data is from 2021 though networth data for billionaires is updated regularly. The visualization was made using HTML, CSS and Javascript code to create interactivity and UI. Data from Bloomberg’s Billionaire’s index , which is the source of Musk’s (and others) estimated wealth, is updated regularly.
Full List of Data Sources:
- Cost of a supertanker’s worth of oil (at $70/barrel): https://en.wikipedia.org/wiki/Oil_tanker
- Cost of a Boeing 777-200ER Airplane: https://en.wikipedia.org/wiki/Boeing_777
- Lebron James and Cristiano Ronaldo Net Worth: https://wealthygorilla.com/top-20-richest-athletes-world/
- Tiger Woods Net Worth: https://wealthygorilla.com/top-20-richest-athletes-world/
- It’s alot of money, but we’ve still got a long way to go:
- Cost of building the Burj Khalifa (world’s tallest building in Dubai): https://en.wikipedia.org/wiki/Burj_Khalifa
- Total Ad Revenue for CNN, Fox News and MSNBC: https://www.pewresearch.org/journalism/fact-sheet/cable-news/
- Ophrah Winfrey Net Worth: https://www.celebritynetworth.com/richest-celebrities/actors/oprah-net-worth/
- Tuition for all 280,000 University of California Students: https://www.ucop.edu/operating-budget/_files/rbudget/2021-22-budget-detail.pdf
- One 40-Foot Shipping Container Full of $100 Bills: self-calculation
- Net Worth of Bottom 33% of Americans: https://dqydj.com/average-median-top-net-worth-percentiles/
- George Lucas Net Worth: https://www.bloomberg.com/billionaires/
- Cost of 2020 Tokyo Olympics: https://www.usnews.com/news/business/articles/2021-08-06/tokyo-olympics-cost-154-billion-what-else-could-that-buy
- Annual Budget of the US Department of Energy: https://en.wikipedia.org/wiki/United_States_Department_of_Energy
- Worldwide Box Office Revenue for Marvel Cinematic Universe (2008-2021): https://www.the-numbers.com/movies/franchise/Marvel-Cinematic-Universe#tab=summary
- Total Amount Spent of Gasoline in the State of Texas in one year: https://www.eia.gov/state/seds/data.php?incfile=/state/seds/sep_fuel/html/fuel_mg.html&sid=US
- Size of Harvard University’s Endowment: https://www.thecrimson.com/article/2021/10/15/endowment-returns-soar-2021/
- Annual Budget of the US Department of Transportation: https://en.wikipedia.org/wiki/United_States_Department_of_Transportation
- Total Gross State Product of Hawaii in 2021: https://en.wikipedia.org/wiki/List_of_states_and_territories_of_the_United_States_by_GDP
- Warren Buffet Net Worth: https://www.bloomberg.com/billionaires/
- State of Texas Operating Budget: https://en.wikipedia.org/wiki/List_of_U.S._state_budgets
- Total Value of all National Football League (NFL) Teams: https://www.profootballnetwork.com/nfl-franchise-values/
- Total Annual Income of 2 Million Residents of Silicon Valley (San Jose-Sunnyvale-Santa Clara CA Metro Area): https://censusreporter.org/profiles/31000US41940-san-jose-sunnyvale-santa-clara-ca-metro-area/
- Total Dollar Value of All US Agricultural Production: https://www.ers.usda.gov/data-products/ag-and-food-statistics-charting-the-essentials/ag-and-food-sectors-and-the-economy/
- Bill Gates Net Worth: https://www.bloomberg.com/billionaires/
- Total Tesla Revenue Since Founding (2008-2021): https://www.statista.com/statistics/272120/revenue-of-tesla/
- Annual Advertising Revenue for Google: https://www.cnbc.com/2021/05/18/how-does-google-make-money-advertising-business-breakdown-.html
- Total Amount Spent on US Residential Electricity In A Year: https://www.eia.gov/state/seds/data.php?incfile=/state/seds/sep_fuel/html/fuel_pr_es.html&sid=US
- Jeff Bezos Net Worth: https://www.bloomberg.com/billionaires/
- Annual Federal Taxes paid in Florida: https://en.wikipedia.org/wiki/Federal_tax_revenue_by_state
- Global Electric Vehicle Market Size in 2020: https://www.globenewswire.com/en/news-release/2021/09/06/2291730/0/en/Electric-Vehicle-Market-Size-Is-Anticipated-to-Grow-USD-1-318-22-Billion-in-2028-at-a-CAGR-of-24-3.html
- Value (i.e. Market Capitalization) of Walt Disney Company: https://www.google.com/finance/quote/DIS:NYSE
- Annual Revenue of Toyota Motor Corporation: https://money.cnn.com/quote/financials/financials.html?symb=TM
- Annual Health Care Expenditures for the entire State of California: https://www.kff.org/other/state-indicator/health-care-expenditures-by-state-of-residence-in-millions/?currentTimeframe=0&sortModel=%7B%22colId%22:%22Location%22,%22sort%22:%22asc%22%7D
- Total Annual Income for 100,000 Average US Households: https://www.census.gov/library/publications/2021/demo/p60-273.html
- Cost of one Gerald Ford Class Aircraft Carrier: https://en.wikipedia.org/wiki/Gerald_R._Ford-class_aircraft_carrier
- Cost to Build California High Speed Rail System: https://en.wikipedia.org/wiki/California_High-Speed_Rail
- Inflation Adjusted Cost of NASA’s Apollo Program: https://www.forbes.com/sites/alexknapp/2019/07/20/apollo-11-facts-figures-business/
- Total Annual Housing and Utilities Expenditures For All 6.6 Million Households in Los Angeles Metro Area: https://www.bls.gov/cex/tables/geographic/mean/cu-msa-west-2-year-average-2020.pdf
- Annual Amount Spent on the Purchase of iPhones: https://www.businessofapps.com/data/apple-statistics/
- Annual Aggregate Salaries of US Workers in 2023 (various occupations): BLS Website: https://www.bls.gov/oes/current/oes_nat.htm
- Consumer Purchases: BEA Website: https://apps.bea.gov/
- Welfare Spending: Pew Research: https://www.pewresearch.org/short-reads/2023/07/19/what-the-data-says-about-food-stamps-in-the-u-s/
- Market Cap or Revenue for large companies : Stock Analysis: https://stockanalysis.com/list/sp-500-stocks/
- Elon Musk Net Worth: https://www.bloomberg.com/billionaires/
Using up our carbon budget
How much more CO2 can we emit if we want to keep the global temperature rise below 1.5°C or 2°C?
Every bit of CO2 we release is one step closer to using up our carbon budget.
Click on the animate button (or use the slider) to see how we have used up our carbon budget to limit global warming to 1.5°C or 2°C.
Climate change is the result of greenhouse gases such as CO2 and methane from human activities. The amount of CO2 and other greenhouse gases in the atmosphere determines how much of the incoming solar radiation is trapped as heat. Since CO2 is the most common greenhouse gas and very long lived in the atmosphere, there’s a good correlation between the total amount of human CO2 emissions and the amount of warming that the earth will experience. This leads to the concept of a carbon budget.
What is the carbon budget?
For every ton of CO2 that is emitted into the atmosphere about half a ton becomes part of the atmosphere for the long term, assuming there’s no massive new program to remove CO2 from the atmosphere. And there’s a direct correlation between the atmospheric concentration of CO2 and the earth’s temperature. Scientists tend to look at milestones of 2°C or 1.5°C when thinking about potential future warming. There is some uncertainty, but the total amount of human CO2 emissions that will lead to a 1.5°C warming from pre-industrial levels is around 2200 billion metric tonnes of CO2 plus or minus a few hundred billion tons (or 460 billion metric tonnes from 2020). This unit is also written as GtCO2 or gigatonnes of CO2. The values for the budget for 2°C warming are 1310 GtCO2 from 2020 or 2993 GtCO2 from pre-industrial levels.
Shown below is a graph from the Carbon Brief that shows the uncertainty in estimates for the remaining carbon budget (from 2018) before having a 50% chance of exceeding 1.5°C warming. As you can see there’s a fairly large range.
Update: The article’s author Zeke Hausfather pointed me to an updated article with newer IPCC estimates for the carbon budget of these two warming milestones. I have updated the code to account for these two new values.
What may happen at 1.5 degrees of warming?
1.5°C (2.7°F) doesn’t sound like alot, but there are some pretty serious potential consequences that we’ll be dealing with. These include increasing the amount or frequency of the following:
- extreme heatwaves
- droughts
- extreme storms and precipitation events
- loss of wildlife and biodiversity
- sea level rise
- and impacts of human health
This NASA article has much more info on the specific issues related to this temperature rise. Ideally we’d keep warming to under 1.5°C but it looks likely that we may exceed 2°C unless we take fairly dramatic action to reduce or CO2 emissions from fossil fuel combustion and use cleaner/lower-carbon sources of energy, like renewables and nuclear power.
From 1750 to 2020, humans have emitted approximately 1683 GtCO2. The IPCC estimates that 460 GtCO2 would put us at 1.5°C warming and 1310 GtCO2 would put us at 2°C warming. These values give us an estimated total carbon budget of 2143 GtCO2 for 1.5°C and 2993 GtCO2 for 2°C warming.
You can really see how we are getting close to using up all of our 1.5°C carbon budget and the speed at which we are using it up, especially in the last few decades.
Sources and Tools:
Annual emissions data is from the Global Carbon Project. The visualization was made using the plotly.js open source graphing library and HTML/CSS/Javascript code for the interactivity and UI.
Visualizing the Orbit of the International Space Station (ISS)
Where is the International Space Station currently? And what pattern does it make as it orbits around the Earth?
This visualization shows the current location of the International Space Station (ISS), actually the point above the Earth that the station is closest to. It is approximately 260 miles (420 km) above the Earth’s surface The station began construction in 1998 and had its first long term residents in 2000.
The visualization can also show the animated future orbital path of the ISS using ephemeris calculations, which makes a nice, cool pattern over an approximately 3.9 day cycle, where it starts to repeat. The animation allows you to view the orbital patterns on the globe (orthographic projection) or a mercator or equirectangular projection.
One of the cooler features is to drag and rotate the globe view while the orbital paths are being drawn. You can also adjust the speed of the orbit as well as keep the ISS centered in your view while the globe spins around underneath it. If you select the “rotate earth” checkbox, it becomes apparent that the ISS is in a circular orbit around the earth and that the pattern being made is simply a function of the earth’s rotation underneath the orbit.
This visualization only shows the approximate location of the ISS as there are several confounding factors that are not represented here. The speed of the ISS changes somewhat over time as the station experiences a small amount of atmospheric drag, which slows the station over time. But it still goes over 7000 meters per second or about 17000 miles per hour. As it slows, its orbit decays so it falls closer to earth and it experiences even more atmospheric drag. Occasionally, the station is boosted up to a higher orbit to counteract this decay. Secondly the earth is not a perfect sphere and this also causes the calculations to be only approximately correct.
Some other cool facts about the International Space Station:
- the angle the orbit makes relative to the equator is 51.6 degrees (i.e. this means the highest and lowest latitudes it will reach are 51.6 degrees North and South and doesn’t orbit over the poles
- the circular orbit around the earth makes a sin wave pattern on 2D map projections (shown on the mercator and equirectangular projections
- one orbit takes about 90 minutes. This means there are approximately 16 orbits per day and astronauts aboard the ISS will see 16 sunrises and sunsets
Other cool space-related orbital art can be seen at the inner planet spirographs.
Here are a couple of images showing the final pattern made by the ISS on different map projections.
Sources and Tools:
I used the satellite.js javascript package and the ISS TLE file to calculate the position of the ISS.
The visualization was made using the d3.js open source graphing library and HTML/CSS/Javascript code for the interactivity and UI.
Visualizing Olympic Sports
See all 339 Olympic Events in the Tokyo 2020/2021 Olympics
It had always seemed like the most decorated US Olympians tended to be swimmers, so I wanted to see how all the various events are distributed across the different types of sports. Each sport (like swimming) has a number of individual events and are show in a treemap as a collection of boxes. And indeed swimming does have the most individual events of any of the sports in the 2020/2021 Olympics.
I also wanted to see how you can categorize the different Olympic events, so I looked at several different dimensions, which are color coded:
- Athlete Gender – Events are categorized into Men’s, Women’s, Mixed and Open Events. Mixed is when a specified number of Men and Women are in an event (i.e. one man and one woman) while Open events can be either Men or Women.
- Team vs Individual – Events are categorized into whether the competitors are individuals or a team (more than one individual)
- Competition Type – Events are categorized into the type of competition, such as a Race (competitors are performing simultaneously to see who finishes first), Individual (where the competitor performs the event by themselves), Opponent (where the competition is one opponent vs another) or Mixed (where there’s some combination of these types)
- How winner are Determined – Events are categorized by the type of scoring: Timed (including all races), Judged, Scored (either in ball sports such as soccer or tennis, or in fighting sports like boxing and wrestling), Completion (where each competitor attempts to complete a jump or lift and the winner is the one who can complete the highest level), Distance (jumping and throwing events) and Hybrid (a combination of these types).
The sports with the largest number of individual events is swimming, then track, cycling, and field. Some the fighting sports have many individual events but they are all exclusive categories (i.e. you can’t compete in two different boxing or wrestling events).
Sources and Tools:
I grabbed a list of Olympic sports from Wikipedia and manually coded the information about gender, competition type and other factors. The visualization uses the plotly.js open source graphing library and HTML/CSS/Javascript code for the interactivity and UI.
Recent Comments